RediSearch
Queries, secondary indexing, and full-text search for Redis


RediSearch is a source available Redis module that provides queryability, secondary indexing, and full-text search for Redis.
Quick Links
Overview
RediSearch provides secondary indexing, full-text search, and a query language for Redis. These feature enable multi-field queries, aggregation,
exact phrase matching, and numeric filtering for text queries.
Client libraries
Official and community client libraries are available for Python, Java, JavaScript, Ruby, Go, C#, and PHP.
See the clients page for the full list.
Cluster support
RediSearch provides a distributed cluster version that scales to billions of documents and hundreds of servers.
Commercial support
Commercial support for RediSearch is provided by Redis Ltd. See the Redis Ltd. website for more info and contact information.
Primary features
RediSearch supports the following features:
- Secondary indexing
- Multi-field queries
- Aggregation
- Full-text indexing of multiple fields in a documents
- Incremental indexing without performance loss
- Document ranking (provided manually by the user at index time)
- Boolean queries with AND, OR, NOT operators between sub-queries
- Optional query clauses
- Prefix-based searches
- Field weights
- Auto-complete suggestions (with fuzzy prefix suggestions)
- Exact-phrase search and slop-based search
- Stemming-based query expansion for many languages (using Snowball)
- Support for custom functions for query expansion and scoring (see Extensions)
- Numeric filters and ranges
- Geo-filtering using the Redis own geo commands
- Unicode support (UTF-8 input required)
- Retrieval of full document contents or only their ids
- Document deletion and updating with index garbage collection
- Partial and conditional document updates
RediSearch is developed and tested on Linux and macOS on x86_64 CPUs.
Atom CPUs are not supported.
References
Videos
- RediSearch? - RedisConf 2020
- RediSearch Overview - RedisConf 2019
- RediSearch & CRDT - Redis Day Tel Aviv 2019
Course
Blog posts
- Introducing RediSearch 2.0
- Getting Started with RediSearch 2.0
- Mastering RediSearch / Part I
- Mastering RediSearch / Part II
- Mastering RediSearch / Part III
- Building Real-Time Full-Text Site Search with RediSearch
- Search Benchmarking: RediSearch vs. Elasticsearch
- RediSearch Version 1.6 Adds Features, Improves Performance
- RediSearch 1.6 Boosts Performance Up to 64%
Mailing List / Forum
Got questions? Feel free to ask at the RediSearch forum.
License
Redis Source Available License Agreement - see LICENSE
1 - Commands
Commands Overview
RediSearch API
Details on module's commands can be filtered for a specific module or command, e.g., FT.
The details also include the syntax for the commands, where:
- Command and subcommand names are in uppercase, for example
FT.CREATE - Optional arguments are enclosed in square brackets, for example
[NOCONTENT] - Additional optional arguments are indicated by three period characters, for example
...
The query commands, i.e. FT.SEARCH and FT.AGGREGATE, require an index name as their first argument, then a query, i.e. hello|world, and finally additional parameters or attributes.
See the quick start page on creating and indexing and start searching.
See the reference page for more details on the various parameters.
2 - Quick start
Quick start guide
Quick Start Guide for RediSearch
Redis Cloud
RediSearch is available on all Redis Cloud managed services. Redis Cloud Essentials offers a completely free managed database up to 30MB.
Get started here
Running with Docker
docker run -p 6379:6379 redislabs/redisearch:latest
Download and running binaries
First download the pre-compiled version from the Redis download center.
Next, run Redis with RediSearch:
$ redis-server --loadmodule /path/to/module/src/redisearch.so
Building and running from source
First, clone the git repo (make sure not to omit the --recursive option, to properly clone submodules):
git clone --recursive https://github.com/RediSearch/RediSearch.git
cd RediSearch
Next, install dependencies:
On macOS:
On Linux:
Next, build:
Finally, run Redis with RediSearch:
For more elaborate build instructions, see the Development page.
Creating an index with fields and weights (default weight is 1.0)
127.0.0.1:6379> FT.CREATE myIdx ON HASH PREFIX 1 doc: SCHEMA title TEXT WEIGHT 5.0 body TEXT url TEXT
OK
Adding documents to the index
127.0.0.1:6379> hset doc:1 title "hello world" body "lorem ipsum" url "http://redis.io"
(integer) 3
Searching the index
127.0.0.1:6379> FT.SEARCH myIdx "hello world" LIMIT 0 10
1) (integer) 1
2) "doc:1"
3) 1) "title"
2) "hello world"
3) "body"
4) "lorem ipsum"
5) "url"
6) "http://redis.io"
!!! note
Input is expected to be valid utf-8 or ASCII. The engine cannot handle wide character unicode at the moment.
Dropping the index
127.0.0.1:6379> FT.DROPINDEX myIdx
OK
Adding and getting Auto-complete suggestions
127.0.0.1:6379> FT.SUGADD autocomplete "hello world" 100
OK
127.0.0.1:6379> FT.SUGGET autocomplete "he"
1) "hello world"
3 - Configuration
Details about configuration options
Run-time configuration
RediSearch supports a few run-time configuration options that should be determined when loading the module. In time more options will be added.
Passing Configuration Options During Loading
In general, passing configuration options is done by appending arguments after the --loadmodule argument in the command line, loadmodule configuration directive in a Redis config file, or the MODULE LOAD command. For example:
In redis.conf:
loadmodule redisearch.so OPT1 OPT2
From redis-cli:
127.0.0.6379> MODULE load redisearch.so OPT1 OPT2
From command line:
$ redis-server --loadmodule ./redisearch.so OPT1 OPT2
Setting Configuration Options At Run-Time
As of v1.4.1, the FT.CONFIG allows setting some options during runtime. In addition, the command can be used to view the current run-time configuration options.
RediSearch configuration options
TIMEOUT
The maximum amount of time in milliseconds that a search query is allowed to run. If this time is exceeded we return the top results accumulated so far, or an error depending on the policy set with ON_TIMEOUT. The timeout can be disabled by setting it to 0.
!!! note
Timeout refers to query time only.
Parsing the query is not counted towards timeout.
If timeout was not reached during the search, finalizing operation such as loading documents' content or reducers, continue.
Default
500
Example
$ redis-server --loadmodule ./redisearch.so TIMEOUT 100
ON_TIMEOUT {policy}
The response policy for queries that exceed the TIMEOUT setting.
The policy can be one of the following:
- RETURN: this policy will return the top results accumulated by the query until it timed out.
- FAIL: will return an error when the query exceeds the timeout value.
Default
RETURN
Example
$ redis-server --loadmodule ./redisearch.so ON_TIMEOUT fail
SAFEMODE
!! Deprecated in v1.6. From this version, SAFEMODE is the default. If you still like to re-enable the concurrent mode for writes, use CONCURRENT_WRITE_MODE !!
If present in the argument list, RediSearch will turn off concurrency for query processing, and work in a single thread.
This is useful if data consistency is extremely important, and avoids a situation where deletion of documents while querying them can cause momentarily inconsistent results (i.e. documents that were valid during the invocation of the query are not returned because they were deleted during query processing).
Default
Off (not present)
Example
$ redis-server --loadmodule ./redisearch.so SAFEMODE
Notes
CONCURRENT_WRITE_MODE
If enabled, write queries will be performed concurrently. For now only the tokenization part is executed concurrently. The actual write operation still requires holding the Redis Global Lock.
Default
Not set - "disabled"
Example
$ redis-server --loadmodule ./redisearch.so CONCURRENT_WRITE_MODE
Notes
EXTLOAD {file_name}
If present, we try to load a RediSearch extension dynamic library from the specified file path. See Extensions for details.
Default
None
Example
$ redis-server --loadmodule ./redisearch.so EXTLOAD ./ext/my_extension.so
MINPREFIX
The minimum number of characters we allow for prefix queries (e.g. hel*). Setting it to 1 can hurt performance.
Default
2
Example
$ redis-server --loadmodule ./redisearch.so MINPREFIX 3
MAXPREFIXEXPANSIONS
The maximum number of expansions we allow for query prefixes. Setting it too high can cause performance issues. If MAXPREFIXEXPANSIONS is reached, the query will continue with the first acquired results.
Default
200
Example
$ redis-server --loadmodule ./redisearch.so MAXPREFIXEXPANSIONS 1000
!!! Note "MAXPREFIXEXPANSIONS replaces the deprecated config word MAXEXPANSIONS."
RediSearch considers these two configurations as synonyms. The synonym was added to be more descriptive.
MAXDOCTABLESIZE
The maximum size of the internal hash table used for storing the documents.
Notice, this configuration doesn't limit the amount of documents that can be stored but only the hash table internal array max size.
Decreasing this property can decrease the memory overhead in case the index holds a small amount of documents that are constantly updated.
Default
1000000
Example
$ redis-server --loadmodule ./redisearch.so MAXDOCTABLESIZE 3000000
MAXSEARCHRESULTS
The maximum number of results to be returned by FT.SEARCH command if LIMIT is used.
Setting value to -1 will remove the limit.
Default
1000000
Example
$ redis-server --loadmodule ./redisearch.so MAXSEARCHRESULTS 3000000
MAXAGGREGATERESULTS
The maximum number of results to be returned by FT.AGGREGATE command if LIMIT is used.
Setting value to -1 will remove the limit.
Default
unlimited
Example
$ redis-server --loadmodule ./redisearch.so MAXAGGREGATERESULTS 3000000
FRISOINI {file_name}
If present, we load the custom Chinese dictionary from the specified path. See Using custom dictionaries for more details.
Default
Not set
Example
$ redis-server --loadmodule ./redisearch.so FRISOINI /opt/dict/friso.ini
CURSOR_MAX_IDLE
The maximum idle time (in ms) that can be set to the cursor api.
Default
"300000"
Example
$ redis-server --loadmodule ./redisearch.so CURSOR_MAX_IDLE 500000
Notes
PARTIAL_INDEXED_DOCS
Enable/disable Redis command filter. The filter optimizes partial updates of hashes
and may avoid reindexing of the hash if changed fields are not part of schema.
Considerations
The Redis command filter will be executed upon each Redis Command. Though the filter is
optimized, this will introduce a small increase in latency on all commands.
This configuration is therefore best used with partial indexed documents where the non-
indexed fields are updated frequently.
Default
"0"
Example
$ redis-server --loadmodule ./redisearch.so PARTIAL_INDEXED_DOCS 1
Notes
GC_SCANSIZE
The garbage collection bulk size of the internal gc used for cleaning up the indexes.
Default
100
Example
$ redis-server --loadmodule ./redisearch.so GC_SCANSIZE 10
GC_POLICY
The policy for the garbage collector (GC). Supported policies are:
- FORK: uses a forked thread for garbage collection (v1.4.1 and above).
This is the default GC policy since version 1.6.1 and is ideal
for general purpose workloads.
- LEGACY: Uses a synchronous, in-process fork. This is ideal for read-heavy
and append-heavy workloads with very few updates/deletes
Default
"FORK"
Example
$ redis-server --loadmodule ./redisearch.so GC_POLICY LEGACY
Notes
- When the
GC_POLICY is FORK it can be combined with the options below.
NOGC
If set, we turn off Garbage Collection for all indexes. This is used mainly for debugging and testing, and should not be set by users.
Default
Not set
Example
$ redis-server --loadmodule ./redisearch.so NOGC
FORK_GC_RUN_INTERVAL
Interval (in seconds) between two consecutive fork GC runs.
Default
"30"
Example
$ redis-server --loadmodule ./redisearch.so GC_POLICY FORK FORK_GC_RUN_INTERVAL 60
Notes
- only to be combined with
GC_POLICY FORK
FORK_GC_RETRY_INTERVAL
Interval (in seconds) in which RediSearch will retry to run fork GC in case of a failure. Usually, a failure could happen when the redis fork api does not allow for more than one fork to be created at the same time.
Default
"5"
Example
$ redis-server --loadmodule ./redisearch.so GC_POLICY FORK FORK_GC_RETRY_INTERVAL 10
Notes
- only to be combined with
GC_POLICY FORK - added in v1.4.16
FORK_GC_CLEAN_THRESHOLD
The fork GC will only start to clean when the number of not cleaned documents is exceeding this threshold, otherwise it will skip this run. While the default value is 100, it's highly recommended to change it to a higher number.
Default
"100"
Example
$ redis-server --loadmodule ./redisearch.so GC_POLICY FORK FORK_GC_CLEAN_THRESHOLD 10000
Notes
- only to be combined with
GC_POLICY FORK - added in v1.4.16
UPGRADE_INDEX
This configuration is a special configuration introduced to upgrade indices from v1.x RediSearch versions, further referred to as 'legacy indices.' This configuration option needs to be given for each legacy index, followed by the index name and all valid option for the index description ( also referred to as the ON arguments for following hashes) as described on ft.create api. See Upgrade to 2.0 for more information.
Default
There is no default for index name, and the other arguments have the same defaults as on FT.CREATE api
Example
$ redis-server --loadmodule ./redisearch.so UPGRADE_INDEX idx PREFIX 1 tt LANGUAGE french LANGUAGE_FIELD MyLang SCORE 0.5 SCORE_FIELD MyScore PAYLOAD_FIELD MyPayload UPGRADE_INDEX idx1
Notes
- If the RDB file does not contain a legacy index that's specified in the configuration, a warning message will be added to the log file and loading will continue.
- If the RDB file contains a legacy index that wasn't specified in the configuration loading will fail and the server won't start.
OSS_GLOBAL_PASSWORD
Global oss cluster password that will be used to connect to other shards.
Default
Not set
Example
$ redis-server --loadmodule ./redisearch.so OSS_GLOBAL_PASSWORD password
Notes
- only relevant when Coordinator is used
- added in v2.0.3
DEFAULT_DIALECT
The default DIALECT to be used by FT.CREATE, FT.AGGREGATE, FT.EXPLAIN, FT.EXPLAINCLI, and FT.SPECLCHECK.
Default
"1"
Example
$ redis-server --loadmodule ./redisearch.so DEFAULT_DIALECT 2
Notes
DIALECT 2 is required for Vector Similarity Search- added in v2.4.3
4 - Developer notes
Notes on debugging, testing and documentation
Developing RediSearch
Developing RediSearch involves setting up the development environment (which can be either Linux-based or macOS-based), building RediSearch, running tests and benchmarks, and debugging both the RediSearch module and its tests.
Cloning the git repository
By invoking the following command, RediSearch module and its submodules are cloned:
git clone --recursive https://github.com/RediSearch/RediSearch.git
Working in an isolated environment
There are several reasons to develop in an isolated environment, like keeping your workstation clean, and developing for a different Linux distribution.
The most general option for an isolated environment is a virtual machine (it's very easy to set one up using Vagrant).
Docker is even a more agile, as it offers an almost instant solution:
search=$(docker run -d -it -v $PWD:/build debian:bullseye bash)
docker exec -it $search bash
Then, from within the container, cd /build and go on as usual.
In this mode, all installations remain in the scope of the Docker container.
Upon exiting the container, you can either re-invoke it with the above docker exec or commit the state of the container to an image and re-invoke it on a later stage:
docker commit $search redisearch1
docker stop $search
search=$(docker run -d -it -v $PWD:/build rediseatch1 bash)
docker exec -it $search bash
You can replace debian:bullseye with your OS of choice, with the host OS being the best choice (so you can run the RediSearch binary on your host once it is built).
Installing prerequisites
To build and test RediSearch one needs to install several packages, depending on the underlying OS. Currently, we support the Ubuntu/Debian, CentOS, Fedora, and macOS.
First, enter RediSearch directory.
If you have gnu make installed, you can execute,
make setup
Alternatively, invoke the following:
./deps/readies/bin/getpy2
./system-setup.py
Note that system-setup.py will install various packages on your system using the native package manager and pip. It will invoke sudo on its own, prompting for permission.
If you prefer to avoid that, you can:
- Review
system-setup.py and install packages manually, - Use
system-setup.py --nop to display installation commands without executing them, - Use an isolated environment like explained above,
- Use a Python virtual environment, as Python installations are known to be sensitive when not used in isolation:
python2 -m virtualenv venv; . ./venv/bin/activate
Installing Redis
As a rule of thumb, you're better off running the latest Redis version.
If your OS has a Redis 6.x package, you can install it using the OS package manager.
Otherwise, you can invoke ./deps/readies/bin/getredis.
Getting help
make help provides a quick summary of the development features:
make setup # install prerequisited (CAUTION: THIS WILL MODIFY YOUR SYSTEM)
make fetch # download and prepare dependant modules
make build # compile and link
COORD=1|oss|rlec # build coordinator (1|oss: Open Source, rlec: Enterprise)
STATIC=1 # build as static lib
LITE=1 # build RediSearchLight
VECSIM_MARCH=arch # architecture for VecSim build
DEBUG=1 # build for debugging
NO_TESTS=1 # disable unit tests
WHY=1 # explain CMake decisions (in /tmp/cmake-why)
FORCE=1 # Force CMake rerun (default)
CMAKE_ARGS=... # extra arguments to CMake
VG=1 # build for Valgrind
SAN=type # build with LLVM sanitizer (type=address|memory|leak|thread)
SLOW=1 # do not parallelize build (for diagnostics)
make parsers # build parsers code
make clean # remove build artifacts
ALL=1 # remove entire artifacts directory
make run # run redis with RediSearch
GDB=1 # invoke using gdb
make test # run all tests (via ctest)
COORD=1|oss|rlec # test coordinator
TEST=regex # run tests that match regex
TESTDEBUG=1 # be very verbose (CTest-related)
CTEST_ARG=... # pass args to CTest
CTEST_PARALLEL=n # run tests in give parallelism
make pytest # run python tests (tests/pytests)
COORD=1|oss|rlec # test coordinator
TEST=name # e.g. TEST=test:testSearch
RLTEST_ARGS=... # pass args to RLTest
REJSON=1|0 # also load RedisJSON module
REJSON_PATH=path # use RedisJSON module at `path`
EXT=1 # External (existing) environment
GDB=1 # RLTest interactive debugging
VG=1 # use Valgrind
VG_LEAKS=0 # do not search leaks with Valgrind
SAN=type # use LLVM sanitizer (type=address|memory|leak|thread)
ONLY_STABLE=1 # skip unstable tests
make c_tests # run C tests (from tests/ctests)
make cpp_tests # run C++ tests (from tests/cpptests)
TEST=name # e.g. TEST=FGCTest.testRemoveLastBlock
make callgrind # produce a call graph
REDIS_ARGS="args"
make pack # create installation packages
COORD=rlec # pack RLEC coordinator ('redisearch' package)
LITE=1 # pack RediSearchLight ('redisearch-light' package)
make deploy # copy packages to S3
make release # release a version
make docs # create documentation
make deploy-docs # deploy documentation
make platform # build for specified platform
OSNICK=nick # platform to build for (default: host platform)
TEST=1 # run tests after build
PACK=1 # create package
ARTIFACTS=1 # copy artifacts to host
make box # create container with volumen mapping into /search
OSNICK=nick # platform spec
make sanbox # create container with CLang Sanitizer
Building from source
make build will build RediSearch.
make build COORD=oss will build OSS RediSearch Coordinator.
make build STATIC=1 will build as a static lib
Notes:
Binary files are placed under bin, according to platform and build variant.
RediSearch uses CMake as its build system. make build will invoke both CMake and the subsequent make command that's required to complete the build.
Use make clean to remove built artifacts. make clean ALL=1 will remove the entire bin subdirectory.
Diagnosing build process
make build will build in parallel by default.
For purposes of build diagnosis, make build SLOW=1 VERBOSE=1 can be used to examine compilation commands.
Running Redis with RediSearch
The following will run redis and load RediSearch module.
make run
You can open redis-cli in another terminal to interact with it.
Running tests
There are several sets of unit tests:
- C tests, located in
tests/ctests, run by make c_tests. - C++ tests (enabled by GTest), located in
tests/cpptests, run by make cpp_tests. - Python tests (enabled by RLTest), located in
tests/pytests, run by make pytest.
One can run all tests by invoking make test.
A single test can be run using the TEST parameter, e.g. make test TEST=regex.
Debugging
To build for debugging (enabling symbolic information and disabling optimization), run make DEBUG=1.
One can the use make run DEBUG=1 to invoke gdb.
In addition to the usual way to set breakpoints in gdb, it is possible to use the BB macro to set a breakpoint inside RediSearch code. It will only have an effect when running under gdb.
Similarly, Python tests in a single-test mode, one can set a breakpoint by using the BB() function inside a test.
5 - Client Libraries
List of RediSearch client libraries
RediSearch has several client libraries, written by the module authors and community members - abstracting the API in different programming languages.
While it is possible and simple to use the raw Redis commands API, in most cases it's easier to just use a client library abstracting it.
Currently available Libraries
Other available Libraries
6 - Administration Guide
Administration of the RediSearch module
6.1 - General Administration
General Administration of the RediSearch module
RediSearch Administration Guide
RediSearch doesn't require any configuration to work, but there are a few things worth noting when running RediSearch on top of Redis.
Persistence
RediSearch supports both RDB and AOF based persistence. For a pure RDB set-up, nothing special is needed beyond the standard Redis RDB configuration.
AOF Persistence
While RediSearch supports working with AOF based persistence, as of version 1.1.0 it does not support "classic AOF" mode, which uses AOF rewriting. Instead, it only supports AOF with RDB preamble mode. In this mode, rewriting the AOF log just creates an RDB file, which is appended to.
To enable AOF persistence with RediSearch, add the two following lines to your redis.conf:
appendonly yes
aof-use-rdb-preamble yes
Master/Slave Replication
RediSearch supports replication inherently, and using a master/slave set-up, you can use slaves for high availability. On top of that, slaves can be used for searching, to load-balance read traffic.
Cluster Support
RediSearch will not work correctly on a cluster. The enterprise version of RediSearch, which is commercially available from Redis Labs, does support a cluster set up and scales to hundreds of nodes, billions of documents and terabytes of data. See the Redis Labs Website for more details.
6.2 - Upgrade to 2.0
Details about upgrading to RediSearch 2.x from 1.x
Upgrade to 2.0 when running in Redis OSS
!!! note
For enterprise upgrade please refer to the following link.
v2 of RediSearch re-architects the way indices are kept in sync with the data. Instead of using FT.ADD command to index documents, RediSearch 2.0 follows hashes that match the index description regardless of how those were inserted or changed on Redis (HSET, HINCR, HDEL). The index description will filter hashes on a prefix of the key, and allows you to construct fine-grained filters with the FILTER option. This description can be defined during index creation (FT.CREATE).
v1.x indices (further referred to as legacy indices) don't have such index description. That is why you will need to supply their descriptions when upgrading to v2. During the upgrade to v2, you should add the descriptions via the module's configuration so RediSearch 2.0 will be able to load these legacy indexes.
UPGRADE_INDEX configuration
The upgrade index configuration allows you to specify the legacy index to upgrade. It needs to specify the index name and all the on hash arguments that can be defined on FT.CREATE command (notice that only the index name is mandatory, the other arguments have default values which are the same as the default values on FT.CREATE command). So for example, if you have a legacy index called idx, in order for RediSearch 2.0 to load it, the following configuration needs to be added to the server on start time:
redis-server --loadmodule redisearch.so UPGRADE_INDEX idx
It is also possible to specify the prefixes to follow. For example, assuming all the documents indexed by idx starts with the prefix idx:, the following will upgrade the legacy index idx:
redis-server --loadmodule redisearch.so UPGRADE_INDEX idx PREFIX 1 idx:
Upgrade Limitations
The way that the upgrade process works behind the scenes is that it redefines the index with the on hash index description given in the configuration and then reindexes the data. This comes with some limitations:
- If
NOSAVE was used, then it's not possible to upgrade because the data for reindexing does not exist. - If you have multiple indices, you need to find the way for RediSearch to identify which hashes belong to which index. You can do it either with a prefix or a filter.
- If you have hashes that are not indexed, you will need to find a way so that RediSearch will be able to identify only the hashes that need to be indexed. This can be done using a prefix or a filter.
7.1 - Query syntax
Details of the query syntax
Search Query Syntax
We support a simple syntax for complex queries with the following rules:
- Multi-word phrases simply a list of tokens, e.g.
foo bar baz, and imply intersection (AND) of the terms. - Exact phrases are wrapped in quotes, e.g
"hello world". - OR Unions (i.e
word1 OR word2), are expressed with a pipe (|), e.g. hello|hallo|shalom|hola. - NOT negation (i.e.
word1 NOT word2) of expressions or sub-queries. e.g. hello -world. As of version 0.19.3, purely negative queries (i.e. -foo or -@title:(foo|bar)) are supported. - Prefix matches (all terms starting with a prefix) are expressed with a
*. For performance reasons, a minimum prefix length is enforced (2 by default, but is configurable) - A special "wildcard query" that returns all results in the index -
* (cannot be combined with anything else). - Selection of specific fields using the syntax
hello @field:world. - Numeric Range matches on numeric fields with the syntax
@field:[{min} {max}]. - Geo radius matches on geo fields with the syntax
@field:[{lon} {lat} {radius} {m|km|mi|ft}] - Tag field filters with the syntax
@field:{tag | tag | ...}. See the full documentation on [tag fields|/Tags]. - Optional terms or clauses:
foo ~bar means bar is optional but documents with bar in them will rank higher. - Fuzzy matching on terms (as of v1.2.0):
%hello% means all terms with Levenshtein distance of 1 from it. - An expression in a query can be wrapped in parentheses to disambiguate, e.g.
(hello|hella) (world|werld). - Query attributes can be applied to individual clauses, e.g.
(foo bar) => { $weight: 2.0; $slop: 1; $inorder: false; } - Combinations of the above can be used together, e.g
hello (world|foo) "bar baz" bbbb
Pure negative queries
As of version 0.19.3 it is possible to have a query consisting of just a negative expression, e.g. -hello or -(@title:(foo|bar)). The results will be all the documents NOT containing the query terms.
!!! warning
Any complex expression can be negated this way, however, caution should be taken here: if a negative expression has little or no results, this is equivalent to traversing and ranking all the documents in the index, which can be slow and cause high CPU consumption.
Field modifiers
As of version 0.12 it is possible to specify field modifiers in the query and not just using the INFIELDS global keyword.
Per query expression or sub-expression, it is possible to specify which fields it matches, by prepending the expression with the @ symbol, the field name and a : (colon) symbol.
If a field modifier precedes multiple words or expressions, it applies only to the adjacent expression.
If a field modifier precedes an expression in parentheses, it applies only to the expression inside the parentheses. The expression should be valid for the specified field, otherwise it is skipped.
Multiple modifiers can be combined to create complex filtering on several fields. For example, if we have an index of car models, with a vehicle class, country of origin and engine type, we can search for SUVs made in Korea with hybrid or diesel engines - with the following query:
FT.SEARCH cars "@country:korea @engine:(diesel|hybrid) @class:suv"
Multiple modifiers can be applied to the same term or grouped terms. e.g.:
FT.SEARCH idx "@title|body:(hello world) @url|image:mydomain"
This will search for documents that have "hello" and "world" either in the body or the title, and the term "mydomain" in their url or image fields.
Numeric filters in query
If a field in the schema is defined as NUMERIC, it is possible to either use the FILTER argument in the Redis request or filter with it by specifying filtering rules in the query. The syntax is @field:[{min} {max}] - e.g. @price:[100 200].
A few notes on numeric predicates
It is possible to specify a numeric predicate as the entire query, whereas it is impossible to do it with the FILTER argument.
It is possible to intersect or union multiple numeric filters in the same query, be it for the same field or different ones.
-inf, inf and +inf are acceptable numbers in a range. Thus greater-than 100 is expressed as [(100 inf].
Numeric filters are inclusive. Exclusive min or max are expressed with ( prepended to the number, e.g. [(100 (200].
It is possible to negate a numeric filter by prepending a - sign to the filter, e.g. returning a result where price differs from 100 is expressed as: @title:foo -@price:[100 100].
Tag filters
RediSearch (starting with version 0.91) allows a special field type called "tag field", with simpler tokenization and encoding in the index. The values in these fields cannot be accessed by general field-less search, and can be used only with a special syntax:
@field:{ tag | tag | ...}
e.g.
@cities:{ New York | Los Angeles | Barcelona }
Tags can have multiple words or include other punctuation marks other than the field's separator (, by default). Punctuation marks in tags should be escaped with a backslash (\). It is also recommended (but not mandatory) to escape spaces; The reason is that if a multi-word tag includes stopwords, it will create a syntax error. So tags like "to be or not to be" should be escaped as "to\ be\ or\ not\ to\ be". For good measure, you can escape all spaces within tags.
Notice that multiple tags in the same clause create a union of documents containing either tags. To create an intersection of documents containing all tags, you should repeat the tag filter several times, e.g.:
# This will return all documents containing all three cities as tags:
@cities:{ New York } @cities:{Los Angeles} @cities:{ Barcelona }
# This will return all documents containing either city:
@cities:{ New York | Los Angeles | Barcelona }
Tag clauses can be combined into any sub-clause, used as negative expressions, optional expressions, etc.
Geo filters in query
As of version 0.21, it is possible to add geo radius queries directly into the query language with the syntax @field:[{lon} {lat} {radius} {m|km|mi|ft}]. This filters the result to a given radius from a lon,lat point, defined in meters, kilometers, miles or feet. See Redis' own GEORADIUS command for more details as it is used internally for that).
Radius filters can be added into the query just like numeric filters. For example, in a database of businesses, looking for Chinese restaurants near San Francisco (within a 5km radius) would be expressed as: chinese restaurant @location:[-122.41 37.77 5 km].
Vector Similarity search in query
It is possible to add vector similarity queries directly into the query language.
The basic syntax is "*=>[ KNN {num|$num} @vector $query_vec ]" for running K nearest neighbors query on @vector field.
It is also possilbe to run a Hybrid Query on filtered results.
A Hybrid query allows the user to specify a filter criteria that ALL results in a KNN query must satisfy. The filter criteria can only include fields with non-vector indexes (e.g. indexes created on scalar values such as TEXT, PHONETIC, NUMERIC, GEO, etc)
The General syntax is {some filter query}=>[ KNN {num|$num} @vector $query_vec]. For example:
@published_year:[2020 2021] - Only entities published between 2020 and 2021.
=> - Separates filter query from vector query.
[KNN {num|$num} @vector_field $query_vec] - Return num nearest neighbors entities where query_vec is similar to the vector stored in @vector_field.
As of version 2.4, we allow vector similarity to be used once in the query. For more information on vector smilarity syntax, see Vector Fields, "Querying vector fields" section.
Prefix matching
On index updating, we maintain a dictionary of all terms in the index. This can be used to match all terms starting with a given prefix. Selecting prefix matches is done by appending * to a prefix token. For example:
hel* world
Will be expanded to cover (hello|help|helm|...) world.
A few notes on prefix searches
As prefixes can be expanded into many many terms, use them with caution. There is no magic going on, the expansion will create a Union operation of all suffixes.
As a protective measure to avoid selecting too many terms, and block redis, which is single threaded, there are two limitations on prefix matching:
Prefixes are limited to 2 letters or more. You can change this number by using the MINPREFIX setting on the module command line.
Expansion is limited to 200 terms or less. You can change this number by using the MAXEXPANSIONS setting on the module command line.
Prefix matching fully supports Unicode and is case insensitive.
Currently, there is no sorting or bias based on suffix popularity, but this is on the near-term roadmap.
Fuzzy matching
As of v1.2.0, the dictionary of all terms in the index can also be used to perform Fuzzy Matching. Fuzzy matches are performed based on Levenshtein distance (LD). Fuzzy matching on a term is performed by surrounding the term with '%', for example:
%hello% world
Will perform fuzzy matching on 'hello' for all terms where LD is 1.
As of v1.4.0, the LD of the fuzzy match can be set by the number of '%' surrounding it, so that %%hello%% will perform fuzzy matching on 'hello' for all terms where LD is 2.
The maximal LD for fuzzy matching is 3.
Wildcard queries
As of version 1.1.0, we provide a special query to retrieve all the documents in an index. This is meant mostly for the aggregation engine. You can call it by specifying only a single star sign as the query string - i.e. FT.SEARCH myIndex *.
This cannot be combined with any other filters, field modifiers or anything inside the query. It is technically possible to use the deprecated FILTER and GEOFILTER request parameters outside the query string in conjunction with a wildcard, but this makes the wildcard meaningless and only hurts performance.
Query attributes
As of version 1.2.0, it is possible to apply specific query modifying attributes to specific clauses of the query.
The syntax is (foo bar) => { $attribute: value; $attribute:value; ...}, e.g:
(foo bar) => { $weight: 2.0; $slop: 1; $inorder: true; }
~(bar baz) => { $weight: 0.5; }
The supported attributes are:
- $weight: determines the weight of the sub-query or token in the overall ranking on the result (default: 1.0).
- $slop: determines the maximum allowed "slop" (space between terms) in the query clause (default: 0).
- $inorder: whether or not the terms in a query clause must appear in the same order as in the query, usually set alongside with
$slop (default: false). - $phonetic: whether or not to perform phonetic matching (default: true). Note: setting this attribute on for fields which were not creates as
PHONETIC will produce an error.
A few query examples
Simple phrase query - hello AND world
hello world
Exact phrase query - hello FOLLOWED BY world
"hello world"
Union: documents containing either hello OR world
hello|world
Not: documents containing hello but not world
hello -world
Intersection of unions
(hello|halo) (world|werld)
Negation of union
hello -(world|werld)
Union inside phrase
(barack|barrack) obama
Optional terms with higher priority to ones containing more matches:
obama ~barack ~michelle
Exact phrase in one field, one word in another field:
@title:"barack obama" @job:president
Combined AND, OR with field specifiers:
@title:"hello world" @body:(foo bar) @category:(articles|biographies)
Prefix Queries:
hello worl*
hel* worl*
hello -worl*
Numeric Filtering - products named "tv" with a price range of 200-500:
@name:tv @price:[200 500]
Numeric Filtering - users with age greater than 18:
@age:[(18 +inf]
Mapping common SQL predicates to RediSearch
| SQL Condition | RediSearch Equivalent | Comments |
|---|
| WHERE x='foo' AND y='bar' | @x:foo @y:bar | for less ambiguity use (@x:foo) (@y:bar) |
| WHERE x='foo' AND y!='bar' | @x:foo -@y:bar | |
| WHERE x='foo' OR y='bar' | (@x:foo)|(@y:bar) | |
| WHERE x IN ('foo', 'bar','hello world') | @x:(foo|bar|"hello world") | quotes mean exact phrase |
| WHERE y='foo' AND x NOT IN ('foo','bar') | @y:foo (-@x:foo) (-@x:bar) | |
| WHERE x NOT IN ('foo','bar') | -@x:(foo|bar) | |
| WHERE num BETWEEN 10 AND 20 | @num:[10 20] | |
| WHERE num >= 10 | @num:[10 +inf] | |
| WHERE num > 10 | @num:[(10 +inf] | |
| WHERE num < 10 | @num:[-inf (10] | |
| WHERE num <= 10 | @num:[-inf 10] | |
| WHERE num < 10 OR num > 20 | @num:[-inf (10] | @num:[(20 +inf] | |
| WHERE name LIKE 'john%' | @name:john* | |
Technical note
The query parser is built using the Lemon Parser Generator and a Ragel based lexer. You can see the grammar definition at the git repo.
7.2 - Stop-words
Stop-words support
Stop-Words
RediSearch has a pre-defined default list of stop-words. These are words that are usually so common that they do not add much information to search, but take up a lot of space and CPU time in the index.
When indexing, stop-words are discarded and not indexed. When searching, they are also ignored and treated as if they were not sent to the query processor. This is done when parsing the query.
At the moment, the default stop-word list applies to all full-text indexes in all languages and can be overridden manually at index creation time.
Default stop-word list
The following words are treated as stop-words by default:
a, is, the, an, and, are, as, at, be, but, by, for,
if, in, into, it, no, not, of, on, or, such, that, their,
then, there, these, they, this, to, was, will, with
Overriding the default stop-words
Stop-words for an index can be defined (or disabled completely) on index creation using the STOPWORDS argument in the [FT.CREATE command.
The format is STOPWORDS {number} {stopword} ... where number is the number of stopwords given. The STOPWORDS argument must come before the SCHEMA argument. For example:
FT.CREATE myIndex STOPWORDS 3 foo bar baz SCHEMA title TEXT body TEXT
Disabling stop-words completely
Disabling stopwords completely can be done by passing STOPWORDS 0 on FT.CREATE.
Avoiding stop-word detection in search queries
In rare use cases, where queries are very long and are guaranteed by the client application to not contain stopwords, it is possible to avoid checking for them when parsing the query. This saves some CPU time and is only worth it if the query has dozens or more terms in it. Using this without verifying that the query doesn't contain stop-words might result in empty queries.
7.3 - Aggregations
Details of FT.AGGREGATE. Grouping and projections and functions
RediSearch Aggregations
Aggregations are a way to process the results of a search query, group, sort and transform them - and extract analytic insights from them. Much like aggregation queries in other databases and search engines, they can be used to create analytics reports, or perform Faceted Search style queries.
For example, indexing a web-server's logs, we can create a report for unique users by hour, country or any other breakdown; or create different reports for errors, warnings, etc.
Core concepts
The basic idea of an aggregate query is this:
- Perform a search query, filtering for records you wish to process.
- Build a pipeline of operations that transform the results by zero or more steps of:
- Group and Reduce: grouping by fields in the results, and applying reducer functions on each group.
- Sort: sort the results based on one or more fields.
- Apply Transformations: Apply mathematical and string functions on fields in the pipeline, optionally creating new fields or replacing existing ones
- Limit: Limit the result, regardless of sorting the result.
- Filter: Filter the results (post-query) based on predicates relating to its values.
The pipeline is dynamic and re-entrant, and every operation can be repeated. For example, you can group by property X, sort the top 100 results by group size, then group by property Y and sort the results by some other property, then apply a transformation on the output.
Figure 1: Aggregation Pipeline Example
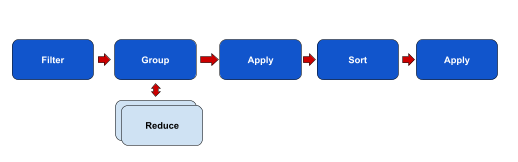
The aggregate request's syntax is defined as follows:
FT.AGGREGATE
{index_name:string}
{query_string:string}
[VERBATIM]
[LOAD {nargs:integer} {property:string} ...]
[GROUPBY
{nargs:integer} {property:string} ...
REDUCE
{FUNC:string}
{nargs:integer} {arg:string} ...
[AS {name:string}]
...
] ...
[SORTBY
{nargs:integer} {string} ...
[MAX {num:integer}] ...
] ...
[APPLY
{EXPR:string}
AS {name:string}
] ...
[FILTER {EXPR:string}] ...
[LIMIT {offset:integer} {num:integer} ] ...
[PARAMS {nargs} {name} {value} ... ]
Parameters in detail
Parameters which may take a variable number of arguments are expressed in the
form of param {nargs} {property_1... property_N}. The first argument to the
parameter is the number of arguments following the parameter. This allows
RediSearch to avoid a parsing ambiguity in case one of your arguments has the
name of another parameter. For example, to sort by first name, last name, and
country, one would specify SORTBY 6 firstName ASC lastName DESC country ASC.
index_name: The index the query is executed against.
query_string: The base filtering query that retrieves the documents. It follows the exact same syntax as the search query, including filters, unions, not, optional, etc.
LOAD {nargs} {property} …: Load document fields from the document HASH objects. This should be avoided as a general rule of thumb. Fields needed for aggregations should be stored as SORTABLE (and optionally UNF to avoid any normalization), where they are available to the aggregation pipeline with very low latency. LOAD hurts the performance of aggregate queries considerably since every processed record needs to execute the equivalent of HMGET against a redis key, which when executed over millions of keys, amounts to very high processing times.
The document ID can be loaded using @__key.
GROUPBY {nargs} {property}: Group the results in the pipeline based on one or more properties. Each group should have at least one reducer (See below), a function that handles the group entries, either counting them or performing multiple aggregate operations (see below).
REDUCE {func} {nargs} {arg} … [AS {name}]: Reduce the matching results in each group into a single record, using a reduction function. For example, COUNT will count the number of records in the group. See the Reducers section below for more details on available reducers.
The reducers can have their own property names using the AS {name} optional argument. If a name is not given, the resulting name will be the name of the reduce function and the group properties. For example, if a name is not given to COUNT_DISTINCT by property @foo, the resulting name will be count_distinct(@foo).
SORTBY {nargs} {property} {ASC|DESC} [MAX {num}]: Sort the pipeline up until the point of SORTBY, using a list of properties. By default, sorting is ascending, but ASC or DESC can be added for each property. nargs is the number of sorting parameters, including ASC and DESC. for example: SORTBY 4 @foo ASC @bar DESC.
MAX is used to optimized sorting, by sorting only for the n-largest elements. Although it is not connected to LIMIT, you usually need just SORTBY … MAX for common queries.
APPLY {expr} AS {name}: Apply a 1-to-1 transformation on one or more properties, and either store the result as a new property down the pipeline, or replace any property using this transformation. expr is an expression that can be used to perform arithmetic operations on numeric properties, or functions that can be applied on properties depending on their types (see below), or any combination thereof. For example: APPLY "sqrt(@foo)/log(@bar) + 5" AS baz will evaluate this expression dynamically for each record in the pipeline and store the result as a new property called baz, that can be referenced by further APPLY / SORTBY / GROUPBY / REDUCE operations down the pipeline.
LIMIT {offset} {num}. Limit the number of results to return just num results starting at index offset (zero based). AS mentioned above, it is much more efficient to use SORTBY … MAX if you are interested in just limiting the output of a sort operation.
However, limit can be used to limit results without sorting, or for paging the n-largest results as determined by SORTBY MAX. For example, getting results 50-100 of the top 100 results is most efficiently expressed as SORTBY 1 @foo MAX 100 LIMIT 50 50. Removing the MAX from SORTBY will result in the pipeline sorting all the records and then paging over results 50-100.
FILTER {expr}. Filter the results using predicate expressions relating to values in each result. They are is applied post-query and relate to the current state of the pipeline. See FILTER Expressions below for full details.
PARAMS {nargs} {name} {value}. Define one or more value parameters. Each parameter has a name and a value. Parameters can be referenced in the query string by a $, followed by the parameter name, e.g., $user, and each such reference in the search query to a parameter name is substituted by the corresponding parameter value. For example, with parameter definition PARAMS 4 lon 29.69465 lat 34.95126, the expression @loc:[$lon $lat 10 km] would be evaluated to @loc:[29.69465 34.95126 10 km]. Parameters cannot be referenced in the query string where concrete values are not allowed, such as in field names, e.g., @loc
Quick example
Let's assume we have log of visits to our website, each record containing the following fields/properties:
- url (text, sortable)
- timestamp (numeric, sortable) - unix timestamp of visit entry.
- country (tag, sortable)
- user_id (text, sortable, not indexed)
Example 1: unique users by hour, ordered chronologically.
First of all, we want all records in the index, because why not. The first step is to determine the index name and the filtering query. A filter query of * means "get all records":
FT.AGGREGATE myIndex "*"
Now we want to group the results by hour. Since we have the visit times as unix timestamps in second resolution, we need to extract the hour component of the timestamp. So we first add an APPLY step, that strips the sub-hour information from the timestamp and stores is as a new property, hour:
FT.AGGREGATE myIndex "*"
APPLY "@timestamp - (@timestamp % 3600)" AS hour
Now we want to group the results by hour, and count the distinct user ids in each hour. This is done by a GROUPBY/REDUCE step:
FT.AGGREGATE myIndex "*"
APPLY "@timestamp - (@timestamp % 3600)" AS hour
GROUPBY 1 @hour
REDUCE COUNT_DISTINCT 1 @user_id AS num_users
Now we'd like to sort the results by hour, ascending:
FT.AGGREGATE myIndex "*"
APPLY "@timestamp - (@timestamp % 3600)" AS hour
GROUPBY 1 @hour
REDUCE COUNT_DISTINCT 1 @user_id AS num_users
SORTBY 2 @hour ASC
And as a final step, we can format the hour as a human readable timestamp. This is done by calling the transformation function timefmt that formats unix timestamps. You can specify a format to be passed to the system's strftime function (see documentation), but not specifying one is equivalent to specifying %FT%TZ to strftime.
FT.AGGREGATE myIndex "*"
APPLY "@timestamp - (@timestamp % 3600)" AS hour
GROUPBY 1 @hour
REDUCE COUNT_DISTINCT 1 @user_id AS num_users
SORTBY 2 @hour ASC
APPLY timefmt(@hour) AS hour
Example 2: Sort visits to a specific URL by day and country:
In this example we filter by the url, transform the timestamp to its day part, and group by the day and country, simply counting the number of visits per group. sorting by day ascending and country descending.
FT.AGGREGATE myIndex "@url:\"about.html\""
APPLY "@timestamp - (@timestamp % 86400)" AS day
GROUPBY 2 @day @country
REDUCE count 0 AS num_visits
SORTBY 4 @day ASC @country DESC
GROUPBY reducers
GROUPBY step work similarly to SQL GROUP BY clauses, and create groups of results based on one or more properties in each record. For each group, we return the "group keys", or the values common to all records in the group, by which they were grouped together - along with the results of zero or more REDUCE clauses.
Each GROUPBY step in the pipeline may be accompanied by zero or more REDUCE clauses. Reducers apply some accumulation function to each record in the group and reduce them into a single record representing the group. When we are finished processing all the records upstream of the GROUPBY step, each group emits its reduced record.
For example, the simplest reducer is COUNT, which simply counts the number of records in each group.
If multiple REDUCE clauses exist for a single GROUPBY step, each reducer works independently on each result and writes its final output once. Each reducer may have its own alias determined using the AS optional parameter. If AS is not specified, the alias is the reduce function and its parameters, e.g. count_distinct(foo,bar).
Supported GROUPBY reducers
COUNT
Format
REDUCE COUNT 0
Description
Count the number of records in each group
COUNT_DISTINCT
Format
REDUCE COUNT_DISTINCT 1 {property}
Description
Count the number of distinct values for property.
!!! note
The reducer creates a hash-set per group, and hashes each record. This can be memory heavy if the groups are big.
COUNT_DISTINCTISH
Format
REDUCE COUNT_DISTINCTISH 1 {property}
Description
Same as COUNT_DISTINCT - but provide an approximation instead of an exact count, at the expense of less memory and CPU in big groups.
!!! note
The reducer uses HyperLogLog counters per group, at ~3% error rate, and 1024 Bytes of constant space allocation per group. This means it is ideal for few huge groups and not ideal for many small groups. In the former case, it can be an order of magnitude faster and consume much less memory than COUNT_DISTINCT, but again, it does not fit every user case.
SUM
Format
REDUCE SUM 1 {property}
Description
Return the sum of all numeric values of a given property in a group. Non numeric values if the group are counted as 0.
MIN
Format
REDUCE MIN 1 {property}
Description
Return the minimal value of a property, whether it is a string, number or NULL.
MAX
Format
REDUCE MAX 1 {property}
Description
Return the maximal value of a property, whether it is a string, number or NULL.
AVG
Format
REDUCE AVG 1 {property}
Description
Return the average value of a numeric property. This is equivalent to reducing by sum and count, and later on applying the ratio of them as an APPLY step.
STDDEV
Format
REDUCE STDDEV 1 {property}
Description
Return the standard deviation of a numeric property in the group.
QUANTILE
Format
REDUCE QUANTILE 2 {property} {quantile}
Description
Return the value of a numeric property at a given quantile of the results. Quantile is expressed as a number between 0 and 1. For example, the median can be expressed as the quantile at 0.5, e.g. REDUCE QUANTILE 2 @foo 0.5 AS median .
If multiple quantiles are required, just repeat the QUANTILE reducer for each quantile. e.g. REDUCE QUANTILE 2 @foo 0.5 AS median REDUCE QUANTILE 2 @foo 0.99 AS p99
TOLIST
Format
REDUCE TOLIST 1 {property}
Description
Merge all distinct values of a given property into a single array.
FIRST_VALUE
Format
REDUCE FIRST_VALUE {nargs} {property} [BY {property} [ASC|DESC]]
Description
Return the first or top value of a given property in the group, optionally by comparing that or another property. For example, you can extract the name of the oldest user in the group:
REDUCE FIRST_VALUE 4 @name BY @age DESC
If no BY is specified, we return the first value we encounter in the group.
If you with to get the top or bottom value in the group sorted by the same value, you are better off using the MIN/MAX reducers, but the same effect will be achieved by doing REDUCE FIRST_VALUE 4 @foo BY @foo DESC.
RANDOM_SAMPLE
Format
REDUCE RANDOM_SAMPLE {nargs} {property} {sample_size}
Description
Perform a reservoir sampling of the group elements with a given size, and return an array of the sampled items with an even distribution.
APPLY expressions
APPLY performs a 1-to-1 transformation on one or more properties in each record. It either stores the result as a new property down the pipeline, or replaces any property using this transformation.
The transformations are expressed as a combination of arithmetic expressions and built in functions. Evaluating functions and expressions is recursively nested and can be composed without limit. For example: sqrt(log(foo) * floor(@bar/baz)) + (3^@qaz % 6) or simply @foo/@bar.
If an expression or a function is applied to values that do not match the expected types, no error is emitted but a NULL value is set as the result.
APPLY steps must have an explicit alias determined by the AS parameter.
Literals inside expressions
- Numbers are expressed as integers or floating point numbers, i.e.
2, 3.141, -34, etc. inf and -inf are acceptable as well. - Strings are quoted with either single or double quotes. Single quotes are acceptable inside strings quoted with double quotes and vice versa. Punctuation marks can be escaped with backslashes. e.g.
"foo's bar" ,'foo\'s bar', "foo \"bar\"" . - Any literal or sub expression can be wrapped in parentheses to resolve ambiguities of operator precedence.
Arithmetic operations
For numeric expressions and properties, we support addition (+), subtraction (-), multiplication (*), division (/), modulo (%) and power (^). We currently do not support bitwise logical operators.
Note that these operators apply only to numeric values and numeric sub expressions. Any attempt to multiply a string by a number, for instance, will result in a NULL output.
List of field APPLY functions
| Function | Description | Example |
|---|
| exists(s) | Checks whether a field exists in a document. | exists(@field) |
List of numeric APPLY functions
| Function | Description | Example |
|---|
| log(x) | Return the logarithm of a number, property or sub-expression | log(@foo) |
| abs(x) | Return the absolute number of a numeric expression | abs(@foo-@bar) |
| ceil(x) | Round to the smallest value not less than x | ceil(@foo/3.14) |
| floor(x) | Round to largest value not greater than x | floor(@foo/3.14) |
| log2(x) | Return the logarithm of x to base 2 | log2(2^@foo) |
| exp(x) | Return the exponent of x, i.e. e^x | exp(@foo) |
| sqrt(x) | Return the square root of x | sqrt(@foo) |
List of string APPLY functions
| Function | | |
|---|
| upper(s) | Return the uppercase conversion of s | upper('hello world') |
| lower(s) | Return the lowercase conversion of s | lower("HELLO WORLD") |
| startswith(s1,s2) | Return 1 if s2 is the prefix of s1, 0 otherwise. | startswith(@field, "company") |
| contains(s1,s2) | Return the number of occurrences of s2 in s1, 0 otherwise. If s2 is an empty string, return length(s1) + 1. | contains(@field, "pa") |
| substr(s, offset, count) | Return the substring of s, starting at offset and having count characters.
If offset is negative, it represents the distance from the end of the string.
If count is -1, it means "the rest of the string starting at offset". | substr("hello", 0, 3)
substr("hello", -2, -1) |
| format( fmt, ...) | Use the arguments following fmt to format a string.
Currently the only format argument supported is %s and it applies to all types of arguments. | format("Hello, %s, you are %s years old", @name, @age) |
| matched_terms([max_terms=100]) | Return the query terms that matched for each record (up to 100), as a list. If a limit is specified, we will return the first N matches we find - based on query order. | matched_terms() |
| split(s, [sep=","], [strip=" "]) | Split a string by any character in the string sep, and strip any characters in strip. If only s is specified, we split by commas and strip spaces. The output is an array. | split("foo,bar") |
List of date/time APPLY functions
| Function | Description |
|---|
| timefmt(x, [fmt]) | Return a formatted time string based on a numeric timestamp value x.
See strftime for formatting options.
Not specifying fmt is equivalent to %FT%TZ. |
| parsetime(timesharing, [fmt]) | The opposite of timefmt() - parse a time format using a given format string |
| day(timestamp) | Round a Unix timestamp to midnight (00:00) start of the current day. |
| hour(timestamp) | Round a Unix timestamp to the beginning of the current hour. |
| minute(timestamp) | Round a Unix timestamp to the beginning of the current minute. |
| month(timestamp) | Round a unix timestamp to the beginning of the current month. |
| dayofweek(timestamp) | Convert a Unix timestamp to the day number (Sunday = 0). |
| dayofmonth(timestamp) | Convert a Unix timestamp to the day of month number (1 .. 31). |
| dayofyear(timestamp) | Convert a Unix timestamp to the day of year number (0 .. 365). |
| year(timestamp) | Convert a Unix timestamp to the current year (e.g. 2018). |
| monthofyear(timestamp) | Convert a Unix timestamp to the current month (0 .. 11). |
List of geo APPLY functions
| Function | Description | Example |
|---|
| geodistance(field,field) | Return distance in meters. | geodistance(@field1,@field2) |
| geodistance(field,"lon,lat") | Return distance in meters. | geodistance(@field,"1.2,-3.4") |
| geodistance(field,lon,lat) | Return distance in meters. | geodistance(@field,1.2,-3.4) |
| geodistance("lon,lat",field) | Return distance in meters. | geodistance("1.2,-3.4",@field) |
| geodistance("lon,lat","lon,lat") | Return distance in meters. | geodistance("1.2,-3.4","5.6,-7.8") |
| geodistance("lon,lat",lon,lat) | Return distance in meters. | geodistance("1.2,-3.4",5.6,-7.8) |
| geodistance(lon,lat,field) | Return distance in meters. | geodistance(1.2,-3.4,@field) |
| geodistance(lon,lat,"lon,lat") | Return distance in meters. | geodistance(1.2,-3.4,"5.6,-7.8") |
| geodistance(lon,lat,lon,lat) | Return distance in meters. | geodistance(1.2,-3.4,5.6,-7.8) |
FT.AGGREGATE myIdx "*" LOAD 1 location APPLY "geodistance(@location,\"-1.1,2.2\")" AS dist
To print out the distance:
FT.AGGREGATE myIdx "*" LOAD 1 location APPLY "geodistance(@location,\"-1.1,2.2\")" AS dist
Note: Geo field must be preloaded using LOAD.
Results can also be sorted by distance:
FT.AGGREGATE idx "*" LOAD 1 @location FILTER "exists(@location)" APPLY "geodistance(@location,-117.824722,33.68590)" AS dist SORTBY 2 @dist DESC
Note: Make sure no location is missing, otherwise the SORTBY will not return any result.
Use FILTER to make sure you do the sorting on all valid locations.
FILTER expressions
FILTER expressions filter the results using predicates relating to values in the result set.
The FILTER expressions are evaluated post-query and relate to the current state of the pipeline. Thus they can be useful to prune the results based on group calculations. Note that the filters are not indexed and will not speed the processing per se.
Filter expressions follow the syntax of APPLY expressions, with the addition of the conditions ==, !=, <, <=, >, >=. Two or more predicates can be combined with logical AND (&&) and OR (||). A single predicate can be negated with a NOT prefix (!).
For example, filtering all results where the user name is 'foo' and the age is less than 20 is expressed as:
FT.AGGREGATE
...
FILTER "@name=='foo' && @age < 20"
...
Several filter steps can be added, although at the same stage in the pipeline, it is more efficient to combine several predicates into a single filter step.
Cursor API
FT.AGGREGATE ... WITHCURSOR [COUNT {read size} MAXIDLE {idle timeout}]
FT.CURSOR READ {idx} {cid} [COUNT {read size}]
FT.CURSOR DEL {idx} {cid}
You can use cursors with FT.AGGREGATE, with the WITHCURSOR keyword. Cursors allow you to
consume only part of the response, allowing you to fetch additional results as needed.
This is much quicker than using LIMIT with offset, since the query is executed only
once, and its state is stored on the server.
To use cursors, specify the WITHCURSOR keyword in FT.AGGREGATE, e.g.
FT.AGGREGATE idx * WITHCURSOR
This will return a response of an array with two elements. The first element is
the actual (partial) results, and the second is the cursor ID. The cursor ID
can then be fed to FT.CURSOR READ repeatedly, until the cursor ID is 0, in
which case all results have been returned.
To read from an existing cursor, use FT.CURSOR READ, e.g.
FT.CURSOR READ idx 342459320
Assuming 342459320 is the cursor ID returned from the FT.AGGREGATE request.
Here is an example in pseudo-code:
response, cursor = FT.AGGREGATE "idx" "redis" "WITHCURSOR";
while (1) {
processResponse(response)
if (!cursor) {
break;
}
response, cursor = FT.CURSOR read "idx" cursor
}
Note that even if the cursor is 0, a partial result may still be returned.
Cursor settings
Read size
You can control how many rows are read per each cursor fetch by using the
COUNT parameter. This parameter can be specified both in FT.AGGREGATE
(immediately after WITHCURSOR) or in FT.CURSOR READ.
FT.AGGREGATE idx query WITHCURSOR COUNT 10
Will read 10 rows at a time.
You can override this setting by also specifying COUNT in CURSOR READ, e.g.
FT.CURSOR READ idx 342459320 COUNT 50
Will return at most 50 results.
The default read size is 1000
Timeouts and limits
Because cursors are stateful resources which occupy memory on the server, they
have a limited lifetime. In order to safeguard against orphaned/stale cursors,
cursors have an idle timeout value. If no activity occurs on the cursor before
the idle timeout, the cursor is deleted. The idle timer resets to 0 whenever
the cursor is read from using CURSOR READ.
The default idle timeout is 300000 milliseconds (or 300 seconds). You can modify
the idle timeout using the MAXIDLE keyword when creating the cursor. Note that
the value cannot exceed the default 300s.
FT.AGGREGATE idx query WITHCURSOR MAXIDLE 10000
Will set the limit for 10 seconds.
Other cursor commands
Cursors can be explicitly deleted using the CURSOR DEL command, e.g.
FT.CURSOR DEL idx 342459320
Note that cursors are automatically deleted if all their results have been
returned, or if they have been timed out.
All idle cursors can be forcefully purged at once using FT.CURSOR GC idx 0 command.
By default, RediSearch uses a lazy throttled approach to garbage collection, which
collects idle cursors every 500 operations, or every second - whichever is later.
7.4 - Tokenization
Controlling Text Tokenization and Escaping
Controlling Text Tokenization and Escaping
At the moment, RediSearch uses a very simple tokenizer for documents and a slightly more sophisticated tokenizer for queries. Both allow a degree of control over string escaping and tokenization.
Note: There is a different mechanism for tokenizing text and tag fields, this document refers only to text fields. For tag fields please refer to the Tag Fields documentation.
The rules of text field tokenization
All punctuation marks and whitespace (besides underscores) separate the document and queries into tokens. e.g. any character of ,.<>{}[]"':;!@#$%^&*()-+=~ will break the text into terms. So the text foo-bar.baz...bag will be tokenized into [foo, bar, baz, bag]
Escaping separators in both queries and documents is done by prepending a backslash to any separator. e.g. the text hello\-world hello-world will be tokenized as [hello-world, hello, world]. NOTE that in most languages you will need an extra backslash when formatting the document or query, to signify an actual backslash, so the actual text in redis-cli for example, will be entered as hello\\-world.
Underscores (_) are not used as separators in either document or query. So the text hello_world will remain as is after tokenization.
Repeating spaces or punctuation marks are stripped.
In Latin characters, everything gets converted to lowercase.
A backslash before the first digit will tokenize it as a term. This will translate - sign as NOT which otherwise will make the number negative. Add a backslash before . if you are searching for a float. (ex. -20 -> {-20} vs -\20 -> {NOT{20}})
7.5 - Sorting
Support for sorting query results
Sorting by Indexed Fields
As of RediSearch 0.15, it is possible to bypass the scoring function mechanism, and order search results by the value of different document properties (fields) directly - even if the sorting field is not used by the query. For example, you can search for first name and sort by last name.
Declaring Sortable Fields
When creating the index with FT.CREATE, you can declare TEXT and NUMERIC properties to be SORTABLE. When a property is sortable, we can later decide to order the results by its values. For example, in the following schema:
> FT.CREATE users SCHEMA first_name TEXT last_name TEXT SORTABLE age NUMERIC SORTABLE
The fields last_name and age are sortable, but first_name isn't. This means we can search by either first and/or last name, and sort by last name or age.
Note on sortable TEXT fields
In the current implementation, when declaring a sortable field, its content gets copied into a special location in the index, for fast access on sorting. This means that making long text fields sortable is very expensive, and you should be careful with it.
Normalization (UNF option)
By default, text fields get normalized and lowercased in a Unicode-safe way when stored for sorting. This means that America and america are considered equal in terms of sorting.
Using the argument UNF (un-normalized form) it is possible to disable the normalization and keep the original form of the value. Therefore, America will come before america.
Specifying SORTBY
If an index includes sortable fields, you can add the SORTBY parameter to the search request (outside the query body), and order the results by it. This overrides the scoring function mechanism, and the two cannot be combined. If WITHSCORES is specified along with SORTBY, the scores returned are simply the relative position of each result in the result set.
The syntax for SORTBY is:
SORTBY {field_name} [ASC|DESC]
field_name must be a sortable field defined in the schema.
ASC means the order will be ascending, DESC that it will be descending.
The default ordering is ASC if not specified otherwise.
Quick example
> FT.CREATE users SCHEMA first_name TEXT SORTABLE last_name TEXT age NUMERIC SORTABLE
# Add some users
> FT.ADD users user1 1.0 FIELDS first_name "alice" last_name "jones" age 35
> FT.ADD users user2 1.0 FIELDS first_name "bob" last_name "jones" age 36
# Searching while sorting
# Searching by last name and sorting by first name
> FT.SEARCH users "@last_name:jones" SORTBY first_name DESC
# Searching by both first and last name, and sorting by age
> FT.SEARCH users "alice jones" SORTBY age ASC
7.6 - Tags
Details about tag fields
Tag Fields
Tag fields are similar to full-text fields but use simpler tokenization and encoding in the index. The values in these fields cannot be accessed by general field-less search and can be used only with a special syntax.
The main differences between tag and full-text fields are:
We do not perform stemming on tag indexes.
The tokenization is simpler: The user can determine a separator (defaults to a comma) for multiple tags, and we only do whitespace trimming at the end of tags. Thus, tags can contain spaces, punctuation marks, accents, etc.
The only two transformations we perform are lower-casing (for latin languages only as of now) and whitespace trimming. Lower-case transformation can be disabled by passing CASESENSITIVE.
Tags cannot be found from a general full-text search. If a document has a field called "tags" with the values "foo" and "bar", searching for foo or bar without a special tag modifier (see below) will not return this document.
The index is much simpler and more compressed: We do not store frequencies, offset vectors of field flags. The index contains only document IDs encoded as deltas. This means that an entry in a tag index is usually one or two bytes long. This makes them very memory efficient and fast.
We can create up to 1024 tag fields per index.
Creating a tag field
Tag fields can be added to the schema in FT.ADD with the following syntax:
FT.CREATE ... SCHEMA ... {field_name} TAG [SEPARATOR {sep}] [CASESENSITIVE]
SEPARATOR defaults to a comma (,), and can be any printable ASCII character. For example:
CASESENSITIVE can be specified to keep the original letters case.
FT.CREATE idx ON HASH PREFIX 1 test: SCHEMA tags TAG SEPARATOR ";"
Querying tag fields
As mentioned above, just searching for a tag without any modifiers will not retrieve documents
containing it.
The syntax for matching tags in a query is as follows (the curly braces are part of the syntax in
this case):
@<field_name>:{ <tag> | <tag> | ...}
For example, this query finds documents with either the tag hello world or foo bar:
FT.SEARCH idx "@tags:{ hello world | foo bar }"
Tag clauses can be combined into any sub-clause, used as negative expressions, optional expressions, etc. For example, given the following index:
FT.CREATE idx ON HASH PREFIX 1 test: SCHEMA title TEXT price NUMERIC tags TAG SEPARATOR ";"
You can combine a full-text search on the title field, a numerical range on price, and match either the foo bar or hello world tag like this:
FT.SEARCH idx "@title:hello @price:[0 100] @tags:{ foo bar | hello world }
Tags support prefix matching with the regular * character:
FT.SEARCH idx "@tags:{ hell* }"
FT.SEARCH idx "@tags:{ hello\\ w* }"
Notice that including multiple tags in the same clause creates a union of all documents that contain any of the included tags. To create an intersection of documents containing all of the given tags, you should repeat the tag filter several times.
For example, imagine an index of travellers, with a tag field for the cities each traveller has visited:
FT.CREATE myIndex ON HASH PREFIX 1 traveller: SCHEMA name TEXT cities TAG
HSET traveller:1 name "John Doe" cities "New York, Barcelona, San Francisco"
For this index, the following query will return all the people who visited at least one of the following cities:
FT.SEARCH myIndex "@cities:{ New York | Los Angeles | Barcelona }"
But the next query will return all people who have visited all three cities:
FT.SEARCH myIndex "@cities:{ New York } @cities:{Los Angeles} @cities:{ Barcelona }"
A tag can include punctuation other than the field's separator (by default, a comma). You do not need to escape punctuation when using the HSET command to add the value to a Redis Hash.
For example, given the following index:
FT.CREATE punctuation ON HASH PREFIX 1 test: SCHEMA tags TAG
You can add tags that contain punctuation like this:
HSET test:1 tags "Andrew's Top 5,Justin's Top 5"
However, when you query for tags that contain punctuation, you must escape that punctuation with a backslash character (\).
NOTE: In most languages you will need an extra backslash. This is also the case in the redis-cli.
For example, querying for the tag Andrew's Top 5 in the redis-cli looks like this:
FT.SEARCH punctuation "@tags:{ Andrew\\'s Top 5 }"
As the examples in this document show, a single tag can include multiple words. We recommend that you escape spaces when querying, though doing so is not required.
You escape spaces the same way that you escape punctuation -- by preceding the space with a backslash character (or two backslashes, depending on the programming language and environment).
Thus, you would escape the tag "to be or not to be" like so when querying in the redis-cli:
FT.SEARCH idx "@tags:{ to\\ be\\ or\\ not\\ to\\ be }"
You should escape spaces because if a tag includes multiple words and some of them are stop words like "to" or "be," a query that includes these words without escaping spaces will create a syntax error.
You can see what that looks like in the following example:
127.0.0.1:6379> FT.SEARCH idx "@tags:{ to be or not to be }"
(error) Syntax error at offset 27 near be
NOTE: Stop words are words that are so common that a search engine ignores them. We have a dedicated page about stop words in RediSearch if you would like to learn more.
Given the potential for syntax errors, we recommend that you escape all spaces within tag queries.
7.7 - Highlighting
Highlighting full-text results
Highlighting API
The highlighting API allows you to have only the relevant portions of document matching a search query returned as a result. This allows users to quickly see how a document relates to their query, with the search terms highlighted, usually in bold letters.
RediSearch implements high performance highlighting and summarization algorithms, with the following API:
Command syntax
FT.SEARCH ...
SUMMARIZE [FIELDS {num} {field}] [FRAGS {numFrags}] [LEN {fragLen}] [SEPARATOR {sepstr}]
HIGHLIGHT [FIELDS {num} {field}] [TAGS {openTag} {closeTag}]
There are two sub-commands commands used for highlighting. One is HIGHLIGHT which surrounds matching text with an open and/or close tag, and the other is SUMMARIZE which splits a field into contextual fragments surrounding the found terms. It is possible to summarize a field, highlight a field, or perform both actions in the same query.
Summarization
FT.SEARCH ...
SUMMARIZE [FIELDS {num} {field}] [FRAGS {numFrags}] [LEN {fragLen}] [SEPARATOR {sepStr}]
Summarization will fragment the text into smaller sized snippets; each snippet will contain the found term(s) and some additional surrounding context.
RediSearch can perform summarization using the SUMMARIZE keyword. If no additional arguments are passed, all returned fields are summarized using built-in defaults.
The SUMMARIZE keyword accepts the following arguments:
FIELDS: If present, must be the first argument. This should be followed
by the number of fields to summarize, which itself is followed by a list of
fields. Each field present is summarized. If no FIELDS directive is passed,
then all fields returned are summarized.
FRAGS: How many fragments should be returned. If not specified, a default of 3 is used.
LEN The number of context words each fragment should contain. Context
words surround the found term. A higher value will return a larger block of
text. If not specified, the default value is 20.
SEPARATOR The string used to divide between individual summary snippets.
The default is ... which is common among search engines; but you may
override this with any other string if you desire to programmatically divide them
later on. You may use a newline sequence, as newlines are stripped from the
result body anyway (thus, it will not be conflated with an embedded newline
in the text)
Highlighting
FT.SEARCH ... HIGHLIGHT [FIELDS {num} {field}] [TAGS {openTag} {closeTag}]
Highlighting will highlight the found term (and its variants) with a user-defined tag. This may be used to display the matched text in a different typeface using a markup language, or to otherwise make the text appear differently.
RediSearch can perform highlighting using the HIGHLIGHT keyword. If no additional arguments are passed, all returned fields are highlighted using built-in defaults.
The HIGHLIGHT keyword accepts the following arguments:
FIELDS If present, must be the first argument. This should be followed
by the number of fields to highlight, which itself is followed by a list of
fields. Each field present is highlighted. If no FIELDS directive is passed,
then all fields returned are highlighted.
TAGS If present, must be followed by two strings; the first is prepended
to each term match, and the second is appended to it. If no TAGS are
specified, a built-in tag value is appended and prepended.
Field selection
If no specific fields are passed to the RETURN, SUMMARIZE, or HIGHLIGHT keywords, then all of a document's fields are returned. However, if any of these keywords contain a FIELD directive, then the SEARCH command will only return the sum total of all fields enumerated in any of those directives.
The RETURN keyword is treated specially, as it overrides any fields specified in SUMMARIZE or HIGHLIGHT.
In the command RETURN 1 foo SUMMARIZE FIELDS 1 bar HIGHLIGHT FIELDS 1 baz, the fields foo is returned as-is, while bar and baz are not returned, because RETURN was specified, but did not include those fields.
In the command SUMMARIZE FIELDS 1 bar HIGHLIGHT FIELDS 1 baz, bar is returned summarized and baz is returned highlighted.
7.8 - Scoring
Full-text scoring functions
Scoring in RediSearch
RediSearch comes with a few very basic scoring functions to evaluate document relevance. They are all based on document scores and term frequency. This is regardless of the ability to use sortable fields. Scoring functions are specified by adding the SCORER {scorer_name} argument to a search query.
If you prefer a custom scoring function, it is possible to add more functions using the Extension API.
These are the pre-bundled scoring functions available in RediSearch and how they work. Each function is mentioned by registered name, that can be passed as a SCORER argument in FT.SEARCH.
TFIDF (default)
Basic TF-IDF scoring with a few extra features thrown inside:
For each term in each result, we calculate the TF-IDF score of that term to that document. Frequencies are weighted based on field weights that are pre-determined, and each term's frequency is normalized by the highest term frequency in each document.
We multiply the total TF-IDF for the query term by the a priory document score given on FT.ADD.
We give a penalty to each result based on "slop" or cumulative distance between the search terms: exact matches will get no penalty, but matches where the search terms are distant see their score reduced significantly. For each 2-gram of consecutive terms, we find the minimal distance between them. The penalty is the square root of the sum of the distances, squared - 1/sqrt(d(t2-t1)^2 + d(t3-t2)^2 + ...).
So for N terms in document D, T1...Tn, the resulting score could be described with this python function:
def get_score(terms, doc):
# the sum of tf-idf
score = 0
# the distance penalty for all terms
dist_penalty = 0
for i, term in enumerate(terms):
# tf normalized by maximum frequency
tf = doc.freq(term) / doc.max_freq
# idf is global for the index, and not calculated each time in real life
idf = log2(1 + total_docs / docs_with_term(term))
score += tf*idf
# sum up the distance penalty
if i > 0:
dist_penalty += min_distance(term, terms[i-1])**2
# multiply the score by the document score
score *= doc.score
# divide the score by the root of the cumulative distance
if len(terms) > 1:
score /= sqrt(dist_penalty)
return score
TFIDF.DOCNORM
Identical to the default TFIDF scorer, with one important distinction:
Term frequencies are normalized by the length of the document (expressed as the total number of terms). The length is weighted, so that if a document contains two terms, one in a field that has a weight 1 and one in a field with a weight of 5, the total frequency is 6, not 2.
FT.SEARCH myIndex "foo" SCORER TFIDF.DOCNORM
BM25
A variation on the basic TF-IDF scorer, see this Wikipedia article for more info.
We also multiply the relevance score for each document by the a priory document score and apply a penalty based on slop as in TFIDF.
FT.SEARCH myIndex "foo" SCORER BM25
DISMAX
A simple scorer that sums up the frequencies of the matched terms; in the case of union clauses, it will give the maximum value of those matches. No other penalties or factors are applied.
It is not a 1 to 1 implementation of Solr's DISMAX algorithm but follows it in broad terms.
FT.SEARCH myIndex "foo" SCORER DISMAX
DOCSCORE
A scoring function that just returns the a priory score of the document without applying any calculations to it. Since document scores can be updated, this can be useful if you'd like to use an external score and nothing further.
FT.SEARCH myIndex "foo" SCORER DOCSCORE
HAMMING
Scoring by the (inverse) Hamming Distance between the documents' payload and the query payload. Since we are interested in the nearest neighbors, we inverse the hamming distance (1/(1+d)) so that a distance of 0 gives a perfect score of 1 and is the highest rank.
This works only if:
- The document has a payload.
- The query has a payload.
- Both are exactly the same length.
Payloads are binary-safe, and having payloads with a length that's a multiple of 64 bits yields slightly faster results.
Example:
127.0.0.1:6379> FT.CREATE idx SCHEMA foo TEXT
OK
127.0.0.1:6379> FT.ADD idx 1 1 PAYLOAD "aaaabbbb" FIELDS foo hello
OK
127.0.0.1:6379> FT.ADD idx 2 1 PAYLOAD "aaaacccc" FIELDS foo bar
OK
127.0.0.1:6379> FT.SEARCH idx "*" PAYLOAD "aaaabbbc" SCORER HAMMING WITHSCORES
1) (integer) 2
2) "1"
3) "0.5" // hamming distance of 1 --> 1/(1+1) == 0.5
4) 1) "foo"
2) "hello"
5) "2"
6) "0.25" // hamming distance of 3 --> 1/(1+3) == 0.25
7) 1) "foo"
2) "bar"
7.9 - Extensions
Details about extensions for query expanders and scoring functions
Extending RediSearch
RediSearch supports an extension mechanism, much like Redis supports modules. The API is very minimal at the moment, and it does not yet support dynamic loading of extensions in run-time. Instead, extensions must be written in C (or a language that has an interface with C) and compiled into dynamic libraries that will be loaded at run-time.
There are two kinds of extension APIs at the moment:
- Query Expanders, whose role is to expand query tokens (i.e. stemmers).
- Scoring Functions, whose role is to rank search results in query time.
Registering and loading extensions
Extensions should be compiled into .so files, and loaded into RediSearch on initialization of the module.
Compiling
Extensions should be compiled and linked as dynamic libraries. An example Makefile for an extension can be found here.
That folder also contains an example extension that is used for testing and can be taken as a skeleton for implementing your own extension.
Loading
Loading an extension is done by appending EXTLOAD {path/to/ext.so} after the loadmodule configuration directive when loading RediSearch. For example:
$ redis-server --loadmodule ./redisearch.so EXTLOAD ./ext/my_extension.so
This causes RediSearch to automatically load the extension and register its expanders and scorers.
Initializing an extension
The entry point of an extension is a function with the signature:
int RS_ExtensionInit(RSExtensionCtx *ctx);
When loading the extension, RediSearch looks for this function and calls it. This function is responsible for registering and initializing the expanders and scorers.
It should return REDISEARCH_ERR on error or REDISEARCH_OK on success.
Example init function
#include <redisearch.h> //must be in the include path
int RS_ExtensionInit(RSExtensionCtx *ctx) {
/* Register a scoring function with an alias my_scorer and no special private data and free function */
if (ctx->RegisterScoringFunction("my_scorer", MyCustomScorer, NULL, NULL) == REDISEARCH_ERR) {
return REDISEARCH_ERR;
}
/* Register a query expander */
if (ctx->RegisterQueryExpander("my_expander", MyExpander, NULL, NULL) ==
REDISEARCH_ERR) {
return REDISEARCH_ERR;
}
return REDISEARCH_OK;
}
Calling your custom functions
When performing a query, you can tell RediSearch to use your scorers or expanders by specifying the SCORER or EXPANDER arguments, with the given alias.
e.g.:
FT.SEARCH my_index "foo bar" EXPANDER my_expander SCORER my_scorer
NOTE: Expander and scorer aliases are case sensitive.
The query expander API
At the moment, we only support basic query expansion, one token at a time. An expander can decide to expand any given token with as many tokens it wishes, that will be Union-merged in query time.
The API for an expander is the following:
#include <redisearch.h> //must be in the include path
void MyQueryExpander(RSQueryExpanderCtx *ctx, RSToken *token) {
...
}
RSQueryExpanderCtx
RSQueryExpanderCtx is a context that contains private data of the extension, and a callback method to expand the query. It is defined as:
typedef struct RSQueryExpanderCtx {
/* Opaque query object used internally by the engine, and should not be accessed */
struct RSQuery *query;
/* Opaque query node object used internally by the engine, and should not be accessed */
struct RSQueryNode **currentNode;
/* Private data of the extension, set on extension initialization */
void *privdata;
/* The language of the query, defaults to "english" */
const char *language;
/* ExpandToken allows the user to add an expansion of the token in the query, that will be
* union-merged with the given token in query time. str is the expanded string, len is its length,
* and flags is a 32 bit flag mask that can be used by the extension to set private information on
* the token */
void (*ExpandToken)(struct RSQueryExpanderCtx *ctx, const char *str, size_t len,
RSTokenFlags flags);
/* SetPayload allows the query expander to set GLOBAL payload on the query (not unique per token)
*/
void (*SetPayload)(struct RSQueryExpanderCtx *ctx, RSPayload payload);
} RSQueryExpanderCtx;
RSToken
RSToken represents a single query token to be expanded and is defined as:
/* A token in the query. The expanders receive query tokens and can expand the query with more query
* tokens */
typedef struct {
/* The token string - which may or may not be NULL terminated */
const char *str;
/* The token length */
size_t len;
/* 1 if the token is the result of query expansion */
uint8_t expanded:1;
/* Extension specific token flags that can be examined later by the scoring function */
RSTokenFlags flags;
} RSToken;
The scoring function API
A scoring function receives each document being evaluated by the query, for final ranking.
It has access to all the query terms that brought up the document,and to metadata about the
document such as its a-priory score, length, etc.
Since the scoring function is evaluated per each document, potentially millions of times, and since
redis is single threaded - it is important that it works as fast as possible and be heavily optimized.
A scoring function is applied to each potential result (per document) and is implemented with the following signature:
double MyScoringFunction(RSScoringFunctionCtx *ctx, RSIndexResult *res,
RSDocumentMetadata *dmd, double minScore);
RSScoringFunctionCtx is a context that implements some helper methods.
RSIndexResult is the result information - containing the document id, frequency, terms, and offsets.
RSDocumentMetadata is an object holding global information about the document, such as its a-priory score.
minSocre is the minimal score that will yield a result that will be relevant to the search. It can be used to stop processing mid-way of before we even start.
The return value of the function is double representing the final score of the result.
Returning 0 causes the result to be counted, but if there are results with a score greater than 0, they will appear above it.
To completely filter out a result and not count it in the totals, the scorer should return the special value RS_SCORE_FILTEROUT (which is internally set to negative infinity, or -1/0).
This is an object containing the following members:
- *void privdata: a pointer to an object set by the extension on initialization time.
- RSPayload payload: A Payload object set either by the query expander or the client.
- int GetSlop(RSIndexResult *res): A callback method that yields the total minimal distance between the query terms. This can be used to prefer results where the "slop" is smaller and the terms are nearer to each other.
RSIndexResult
This is an object holding the information about the current result in the index, which is an aggregate of all the terms that resulted in the current document being considered a valid result.
See redisearch.h for details
This is an object describing global information, unrelated to the current query, about the document being evaluated by the scoring function.
Example query expander
This example query expander expands each token with the term foo:
#include <redisearch.h> //must be in the include path
void DummyExpander(RSQueryExpanderCtx *ctx, RSToken *token) {
ctx->ExpandToken(ctx, strdup("foo"), strlen("foo"), 0x1337);
}
Example scoring function
This is an actual scoring function, calculating TF-IDF for the document, multiplying that by the document score, and dividing that by the slop:
#include <redisearch.h> //must be in the include path
double TFIDFScorer(RSScoringFunctionCtx *ctx, RSIndexResult *h, RSDocumentMetadata *dmd,
double minScore) {
// no need to evaluate documents with score 0
if (dmd->score == 0) return 0;
// calculate sum(tf-idf) for each term in the result
double tfidf = 0;
for (int i = 0; i < h->numRecords; i++) {
// take the term frequency and multiply by the term IDF, add that to the total
tfidf += (float)h->records[i].freq * (h->records[i].term ? h->records[i].term->idf : 0);
}
// normalize by the maximal frequency of any term in the document
tfidf /= (double)dmd->maxFreq;
// multiply by the document score (between 0 and 1)
tfidf *= dmd->score;
// no need to factor the slop if tfidf is already below minimal score
if (tfidf < minScore) {
return 0;
}
// get the slop and divide the result by it, making sure we prefer results with closer terms
tfidf /= (double)ctx->GetSlop(h);
return tfidf;
}
7.10 - Stemming
Stemming support
Stemming Support
RediSearch supports stemming - that is adding the base form of a word to the index. This allows the query for "going" to also return results for "go" and "gone", for example.
The current stemming support is based on the Snowball stemmer library, which supports most European languages, as well as Arabic and other. We hope to include more languages soon (if you need a specific language support, please open an issue).
For further details see the Snowball Stemmer website.
Supported languages
The following languages are supported and can be passed to the engine when indexing or querying, with lowercase letters:
- arabic
- armenian
- danish
- dutch
- english
- finnish
- french
- german
- hungarian
- italian
- norwegian
- portuguese
- romanian
- russian
- serbian
- spanish
- swedish
- tamil
- turkish
- yiddish
- chinese (see below)
Chinese support
Indexing a Chinese document is different than indexing a document in most other languages because of how tokens are extracted. While most languages can have their tokens distinguished by separation characters and whitespace, this is not common in Chinese.
Chinese tokenization is done by scanning the input text and checking every character or sequence of characters against a dictionary of predefined terms and determining the most likely (based on the surrounding terms and characters) match.
RediSearch makes use of the Friso chinese tokenization library for this purpose. This is largely transparent to the user and often no additional configuration is required.
Using custom dictionaries
If you wish to use a custom dictionary, you can do so at the module level when loading the module. The FRISOINI setting can point to the location of a friso.ini file which contains the relevant settings and paths to the dictionary files.
Note that there is no "default" friso.ini file location. RedisSearch comes with its own friso.ini and dictionary files which are compiled into the module binary at build-time.
7.11 - Synonym
Synonym support
Synonyms Support
Overview
RediSearch supports synonyms - that is searching for synonyms words defined by the synonym data structure.
The synonym data structure is a set of groups, each group contains synonym terms. For example, the following synonym data structure contains three groups, each group contains three synonym terms:
{boy, child, baby}
{girl, child, baby}
{man, person, adult}
When these three groups are located inside the synonym data structure, it is possible to search for 'child' and receive documents contains 'boy', 'girl', 'child' and 'baby'.
The synonym search technique
We use a simple HashMap to map between the terms and the group ids. During building the index, we check if the current term appears in the synonym map, and if it does we take all the group ids that the term belongs to.
For each group id, we add another record to the inverted index called "~<id>" that contains the same information as the term itself. When performing a search, we check if the searched term appears in the synonym map, and if it does we take all the group ids the term is belong to. For each group id, we search for "~<id>" and return the combined results. This technique ensures that we return all the synonyms of a given term.
Handling concurrency
Since the indexing is performed in a separate thread, the synonyms map may change during the indexing, which in turn may cause data corruption or crashes during indexing/searches. To solve this issue, we create a read-only copy for indexing purposes. The read-only copy is maintained using ref count.
As long as the synonyms map does not change, the original synonym map holds a reference to its read-only copy so it will not be freed. Once the data inside the synonyms map has changed, the synonyms map decreses the reference count of its read only copy. This ensures that when all the indexers are done using the read only copy, then the read only copy will automatically freed. Also it ensures that the next time an indexer asks for a read-only copy, the synonyms map will create a new copy (contains the new data) and return it.
Quick example
# Create an index
> FT.CREATE idx schema t text
# Create a synonym group
> FT.SYNUPDATE idx group1 hello world
# Insert documents
> HSET foo t hello
(integer) 1
> HSET bar t world
(integer) 1
# Search
> FT.SEARCH idx hello
1) (integer) 2
2) "foo"
3) 1) "t"
2) "hello"
4) "bar"
5) 1) "t"
2) "world"
7.12 - Payload
Payload support(deprecated)
Document Payloads
!!! note
The payload feature is deprecated in 2.0
Usually, RediSearch stores documents as hash keys. But if you want to access some data for aggregation or scoring functions, we might want to store that data as an inline payload. This will allow us to evaluate properties of a document for scoring purposes at very low cost.
Since the scoring functions already have access to the DocumentMetaData, which contains document flags and score, We can add custom payloads that can be evaluated in run-time.
Payloads are NOT indexed and are not treated by the engine in any way. They are simply there for the purpose of evaluating them in query time, and optionally retrieving them. They can be JSON objects, strings, or preferably, if you are interested in fast evaluation, some sort of binary encoded data which is fast to decode.
Adding payloads for documents
When inserting a document using FT.ADD, you can ask RediSearch to store an arbitrary binary safe string as the document payload. This is done with the PAYLOAD keyword:
FT.ADD {index_name} {doc_id} {score} PAYLOAD {payload} FIELDS {field} {data}...
Evaluating payloads in query time
When implementing a scoring function, the signature of the function exposed is:
double (*ScoringFunction)(DocumentMetadata *dmd, IndexResult *h);
!!! note
Currently, scoring functions cannot be dynamically added, and forking the engine and replacing them is required.
DocumentMetaData includes a few fields, one of them being the payload. It wraps a simple byte array with arbitrary length:
typedef struct {
char *data,
uint32_t len;
} DocumentPayload;
If no payload was set to the document, it is simply NULL. If it is not, you can go ahead and decode it. It is recommended to encode some metadata about the payload inside it, like a leading version number, etc.
Retrieving payloads from documents
When searching, it is possible to request the document payloads from the engine.
This is done by adding the keyword WITHPAYLOADS to FT.SEARCH.
If WITHPAYLOADS is set, the payloads follow the document id in the returned result.
If WITHSCORES is set as well, the payloads follow the scores. e.g.:
127.0.0.1:6379> FT.CREATE foo SCHEMA bar TEXT
OK
127.0.0.1:6379> FT.ADD foo doc2 1.0 PAYLOAD "hi there!" FIELDS bar "hello"
OK
127.0.0.1:6379> FT.SEARCH foo "hello" WITHPAYLOADS WITHSCORES
1) (integer) 1
2) "doc2" # id
3) "1" # score
4) "hi there!" # payload
5) 1) "bar" # fields
2) "hello"
7.13 - Spellchecking
Query spelling correction support
Query Spelling Correction
Query spelling correction, a.k.a "did you mean", provides suggestions for misspelled search terms. For example, the term 'reids' may be a misspelled 'redis'.
In such cases and as of v1.4 RediSearch can be used for generating alternatives to misspelled query terms. A misspelled term is a full text term (i.e., a word) that is:
- Not a stop word
- Not in the index
- At least 3 characters long
The alternatives for a misspelled term are generated from the corpus of already-indexed terms and, optionally, one or more custom dictionaries. Alternatives become spelling suggestions based on their respective Levenshtein distances (LD) from the misspelled term. Each spelling suggestion is given a normalized score based on its occurances in the index.
To obtain the spelling corrections for a query, refer to the documentation of the FT.SPELLCHECK command.
Custom dictionaries
A dictionary is a set of terms. Dictionaries can be added with terms, have terms deleted from them and have their entire contents dumped using the FT.DICTADD, FT.DICTDEL and FT.DICTDUMP commands, respectively.
Dictionaries can be used to modify the behavior of RediSearch's query spelling correction, by including or excluding their contents from potential spelling correction suggestions.
When used for term inclusion, the terms in a dictionary can be provided as spelling suggestions regardless their occurances (or lack of) in the index. Scores of suggestions from inclusion dictionaries are always 0.
Conversely, terms in an exlusion dictionary will never be returned as spelling alternatives.
7.14 - Phonetic
Phonetic matching
Phonetic Matching
Phonetic matching, a.k.a "Jon or John", allows searching for terms based on their pronunciation. This capability can be a useful tool when searching for names of people.
Phonetic matching is based on the use of a phonetic algorithm. A phonetic algorithm transforms the input term to an approximate representation of its pronunciation. This allows indexing terms, and consequently searching, by their pronunciation.
As of v1.4 RediSearch provides phonetic matching via the definition of text fields with the PHONETIC attribute. This causes the terms in such fields to be indexed both by their textual value as well as their phonetic approximation.
Performing a search on PHONETIC fields will, by default, also return results for phonetically similar terms. This behavior can be controlled with the $phonetic query attribute.
Phonetic algorithms support
RediSearch currently supports a single phonetic algorithm, the Double Metaphone (DM). It uses the implementation at slacy/double-metaphone, which provides general support for Latin languages.
7.15 - Vector similarity
Details about vector fields and vector similarity queries
Vector Fields
Vector fields offers the ability to use vector similarity queries in the FT.SEARCH command.
Vector Similarity search capability offers the ability to load, index and query vectors stored as fields in a redis hashes.
At present, the key functionalites offered are:
Realtime vector indexing supporting 2 Indexing Methods -
Realtime vector update/delete - triggering update of the index.
K nearest neighbors queries supporting 3 distance metrics to measure the degree of similarity between vectors. Metrics:
L2 - Euclidean distance between two vectors.
IP - Internal product of two vectors.
COSINE - Cosine similarity of two vectors.
Creating a vector field
Vector fields can be added to the schema in FT.CREATE with the following syntax:
FT.CREATE ... SCHEMA ... {field_name} VECTOR {algorithm} {count} [{attribute_name} {attribute_value} ...]
{algorithm}
Must be specified and be a supported vector similarity index algorithm. the supported algorithms are:
FLAT - brute force algorithm.
HNSW - Hierarchical Navigable Small World algorithm.
The algorithm attribute specify which algorithm to use when searching for the k most similar vectors in the index.
{count}
Specify the number of attributes for the index. Must be specified.
Notice that this attribute counts the total number of attributes passed for the index in the command,
although algorithm parameters should be submitted as named arguments. For example:
FT.CREATE my_idx SCHEMA vec_field VECTOR FLAT 6 TYPE FLOAT32 DIM 128 DISTANCE_METRIC L2
Here we pass 3 parameters for the index (TYPE, DIM, DISTANCE_METRIC), and count counts the total number of attributes (6).
{attribute_name} {attribute_value}
Algorithm attributes for the creation of the vector index. Every algorithm has its own mandatory and optional attributes.
Specific creation attributes per algorithm
FLAT
HNSW
Querying vector fields
We allow using vector similarity queries in the FT.SEARCH "query" parameter. The syntax for vector similarity queries is *=>[{vector similarity query}] for running the query on an entire vector field, or {primary filter query}=>[{vector similarity query}] for running similarity query on the result of the primary filter query. To use a vector similarity query, you must specify the option DIALECT 2 in the command itself, or by setting the DEFAULT_DIALECT option to 2, either with the commandFT.CONFIG SET or when loading the redisearch module and passing it the argument DEFAULT_DIALECT 2.
As of version 2.4, we allow vector similarity to be used once in the query, and over the entire query filter.
The {vector similarity query} part inside the square brackets needs to be in the following format:
KNN { number | $number_attribute } @{vector field} $blob_attribute [{vector query param name} {value|$value_attribute} [...]] [ AS {score field name | $score_field_name_attribute}]
Every "*_attribute" parameter should refer to an attribute in the PARAMS section.
{ number | $number_attribute } - The number of requested results ("K").
@{vector field} - vector field should be a name of a vector field in the index.
$blob_attribute - An attribute that holds the query vector as blob. must be passed through the PARAMS section.
[{vector query param name} {value|$value_attribute} [...]] - An optional part for passing vector similarity query parameters. Parameters should come in key-value pairs and should be valid parameters for the query. see what runtime parameters are valid for each algorithm.
[ AS {score field name | $score_field_name_attribute}] - An optional part for specifying a score field name, for later sorting by the similarity score. By default the score field name is "__{vector field}_score" and it can be used for sorting without using AS {score field name} in the query.
Specific runtime attributes per algorithm
FLAT
Currently there are no runtime parameters available for FLAT indexes
HNSW
Optional parameters
- EF_RUNTIME -
The number of maximum top candidates to hold during the KNN search. Higher values of
EF_RUNTIME will lead to a more accurate results on the expense of a longer runtime. Defaults to the EF_RUNTIME value passed on creation (which defaults to 10).
A few notes
Although specifing K requested results, the default LIMIT in RediSearch is 10, so for getting all the returned results, make sure to specify LIMIT 0 {K} in your command.
By default, the resluts are sorted by their documents default RediSearch score. for getting the results sorted by similarity score, use SORTBY {score field name} as explained earlier.
Examples for querying vector fields
FT.SEARCH idx "*=>[KNN 100 @vec $BLOB]" PARAMS 2 BLOB "\12\a9\f5\6c" DIALECT 2
FT.SEARCH idx "*=>[KNN 100 @vec $BLOB]" PARAMS 2 BLOB "\12\a9\f5\6c" SORTBY __vec_score DIALECT 2
FT.SEARCH idx "*=>[KNN $K @vec $BLOB EF_RUNTIME $EF]" PARAMS 6 BLOB "\12\a9\f5\6c" K 10 EF 150 DIALECT 2
FT.SEARCH idx "*=>[KNN $K @vec $BLOB AS my_scores]" PARAMS 4 BLOB "\12\a9\f5\6c" K 10 SORTBY my_scores DIALECT 2
FT.SEARCH idx "(@title:Dune @num:[2020 2022])=>[KNN $K @vec $BLOB AS my_scores]" PARAMS 4 BLOB "\12\a9\f5\6c" K 10 SORTBY my_scores DIALECT 2
FT.SEARCH idx "(@type:{shirt} ~@color:{blue})=>[KNN $K @vec $BLOB AS my_scores]" PARAMS 4 BLOB "\12\a9\f5\6c" K 10 SORTBY my_scores DIALECT 2
8 - Design Documents
Design Documents details
8.1 - Internal design
Details about design choices and implementations
RediSearch internal design
RediSearch implements inverted indexes on top of Redis, but unlike previous implementations of Redis inverted indexes, it uses custom data encoding, that allows more memory and CPU efficient searches, and more advanced search features.
This document details some of the design choices and how these features are implemented.
Intro: Redis String DMA
The main feature that this module takes advantage of, is Redis Modules Strings DMA, or Direct Memory Access.
This feature is simple yet very powerful. It basically allows modules to allocate data on Redis string keys,then get a direct pointer to the data allocated by this key, without copying or serializing it.
This allows very fast access to huge amounts of memory, and since from the module's perspective, the string value is exposed simply as char *, it can be cast to any data structure.
You simply call RedisModule_StringTruncate to resize a memory chunk to the size needed, and RedisModule_StringDMA to get direct access to the memory in that key. See https://github.com/RedisLabs/RedisModulesSDK/blob/master/FUNCTIONS.md#redismodule_stringdma
We use this API in the module mainly to encode inverted indexes, and for other auxiliary data structures besides that.
A generic "Buffer" implementation using DMA strings can be found in redis_buffer.c. It automatically resizes the Redis string it uses as raw memory when the capacity needs to grow.
Inverted index encoding
An Inverted Index is the data structure at the heart of all search engines. The idea is simple - per each word or search term, we save a list of all the documents it appears in, and other data, such as term frequency, the offsets where the term appeared in the document, and more. Offsets are used for "exact match" type searches, or for ranking of results.
When a search is performed, we need to either traverse such an index, or intersect or union two or more indexes. Classic Redis implementations of search engines use sorted sets as inverted indexes. This works but has significant memory overhead, and also does not allow for encoding of offsets, as explained above.
RediSearch uses String DMA (see above) to efficiently encode inverted indexes. It combines Delta Encoding and Varint Encoding to encode entries, minimizing space used for indexes, while keeping decompression and traversal efficient.
For each "hit" (document/word entry), we encode:
- The document Id as a delta from the previous document.
- The term frequency, factored by the document's rank (see below)
- Flags, that can be used to filter only specific fields or other user-defined properties.
- An Offset Vector, of all the document offsets of the word.
!!! note
Document ids as entered by the user are converted to internal incremental document ids, that allow delta encoding to be efficient, and let the inverted indexes be sorted by document id.
This allows for a single index hit entry to be encoded in as little as 6 bytes
(Note that this is the best case. depending on the number of occurrences of the word in the document, this can get much higher).
To optimize searches, we keep two additional auxiliary data structures in different DMA string keys:
- Skip Index: We keep a table of the index offset of 1/50 of the index entries. This allows faster lookup when intersecting inverted indexes, as not the entire list must be traversed.
- Score Index: In simple single-word searches, there is no real need to traverse all the results, just the top N results the user is interested in. So we keep an auxiliary index of the top 20 or so entries for each term and use them when applicable.
Document and result ranking
Each document entered to the engine using FT.ADD, has a user assigned rank, between 0 and 1.0. This is used in combination with TF-IDF scoring of each word, to rank the results.
As an optimization, each inverted index hit is encoded with TF*Document_rank as its score, and only IDF is applied during searches. This may change in the future.
On top of that, in the case of intersection queries, we take the minimal distance between the terms in the query, and factor that into the ranking. The closest the terms are to each other, the better the result.
When searching, we keep a priority queue of the top N results requested, and eventually return them, sorted by rank.
Index Specs and field weights
When creating an "index" using FT.CREATE, the user specifies the fields to be indexed, and their respective weights. This can be used to give some document fields, like a title, more weight in ranking results.
For example:
FT.CREATE my_index title 10.0 body 1.0 url 2.0
Will create an index on fields named title, body and url, with scores of 10, 1 and 2 respectively.
When documents are indexed, the weights are taken from the saved Index Spec, that is stored in a special redis key, and only fields that are specified in this spec are indexed.
Document data storage
It is not mandatory to save the document data when indexing a document (specifying NOSAVE for FT.ADD will cause the document to be indexed but not saved).
If the user does save the document, we simply create a HASH key in Redis, containing all fields (including ones not indexed), and upon search, we simply perform an HGETALL query on each retrieved document, returning its entire data.
TODO: Document snippets should be implemented down the road,
Query Execution Engine
We use a chained-iterator based approach to query execution, similar to Python generators in concept.
We simply chain iterators that yield index hits. Those can be:
- Read Iterators, reading hits one by one from an inverted index. i.e.
hello - Intersect Iterators, aggregating two or more iterators, yielding only their intersection points. i.e.
hello AND world - Exact Intersect Iterators - same as above, but yielding results only if the intersection is an exact phrase. i.e.
hello NEAR world - Union Iterators - combining two or more iterators, and yielding a union of their hits. i.e.
hello OR world
These are combined based on the query as an execution plan that is evaluated lazily. For example:
hello ==> read("hello")
hello world ==> intersect( read("hello"), read("world") )
"hello world" ==> exact_intersect( read("hello"), read("world") )
"hello world" foo ==> intersect(
exact_intersect(
read("hello"),
read("world")
),
read("foo")
)
All these iterators are lazy evaluated, entry by entry, with constant memory overhead.
The "root" iterator is read by the query execution engine, and filtered for the top N results in it.
Numeric Filters
We support defining a field in the index schema as "NUMERIC", meaning you will be able to limit search results only to ones where the given value falls within a specific range. Filtering is done by adding FILTER predicates (more than one is supported) to your query. e.g.:
FT.SEARCH products "hd tv" FILTER price 100 (300
The filter syntax follows the ZRANGEBYSCORE semantics of Redis, meaning -inf and +inf are supported, and prepending ( to a number means an exclusive range.
As of release 0.6, the implementation uses a multi-level range tree, saving ranges at multiple resolutions, to allow efficient range scanning. Adding numeric filters can accelerate slow queries if the numeric range is small relative to the entire span of the filtered field. For example, a filter on dates focusing on a few days out of years of data, can speed a heavy query by an order of magnitude.
Auto-Complete and Fuzzy Suggestions
Another important feature for RediSearch is its auto-complete or suggest commands. It allows you to create dictionaries of weighted terms, and then query them for completion suggestions to a given user prefix. For example, if we put the term “lcd tv” into a dictionary, sending the prefix “lc” will return it as a result. The dictionary is modeled as a compressed trie (prefix tree) with weights, that is traversed to find the top suffixes of a prefix.
RediSearch also allows for Fuzzy Suggestions, meaning you can get suggestions to user prefixes even if the user has a typo in the prefix. This is enabled using a Levenshtein Automaton, allowing efficient searching of the dictionary for all terms within a maximal Levenshtein distance of a term or prefix. Then suggested are weighted based on both their original score and distance from the prefix typed by the user. Currently we support (for performance reasons) only suggestions where the prefix is up to 1 Levenshtein distance away from the typed prefix.
However, since searching for fuzzy prefixes, especially very short ones, will traverse an enormous amount of suggestions (in fact, fuzzy suggestions for any single letter will traverse the entire dictionary!), it is recommended to use this feature carefully, and only when considering the performance penalty it incurs. Since Redis is single threaded, blocking it for any amount of time means no other queries can be processed at that time.
To support unicode fuzzy matching, we use 16-bit "runes" inside the trie and not bytes. This increases memory consumption if the text is purely ASCII, but allows completion with the same level of support to all modern languages. This is done in the following manner:
- We assume all input to FT.SUG* commands is valid utf-8.
- We convert the input strings to 32-bit Unicode, optionally normalizing, case-folding and removing accents on the way. If the conversion fails it's because the input is not valid utf-8.
- We trim the 32-bit runes to 16-bit runes using the lower 16 bits. These can be used for insertion, deletion, and search.
- We convert the output of searches back to utf-8.
8.2 - Technical overview
Technical details of the internal design of indexing and querying with RediSearch
RediSearch Technical Overview
Abstract
RediSearch is a powerful text search and secondary indexing engine, built on top of Redis as a Redis Module.
Unlike other Redis search libraries, it does not use the internal data structures of Redis like sorted sets. Using its own highly optimized data structures and algorithms, it allows for advanced search features, high performance, and low memory footprint. It can perform simple text searches, as well as complex structured queries, filtering by numeric properties and geographical distances.
RediSearch supports continuous indexing with no performance degradation, maintaining concurrent loads of querying and indexing. This makes it ideal for searching frequently updated databases, without the need for batch indexing and service interrupts.
RediSearch's Enterprise version supports scaling the search engine across many servers, allowing it to easily grow to billions of documents on hundreds of servers.
All of this is done while taking advantage of Redis' robust architecture and infrastructure. Utilizing Redis' protocol, replication, persistence, clustering - RediSearch delivers a powerful yet simple to manage and maintain search and indexing engine, that can be used as a standalone database, or to augment existing Redis databases with advanced powerful indexing capabilities.
Main features
- Full-Text indexing of multiple fields in a document, including:
- Exact phrase matching.
- Stemming in many languages.
- Chinese tokenization support.
- Prefix queries.
- Optional, negative and union queries.
- Distributed search on billions of documents.
- Numeric property indexing.
- Geographical indexing and radius filters.
- Incremental indexing without performance loss.
- A structured query language for advanced queries:
- Unions and intersections
- Optional and negative queries
- Tag filtering
- Prefix matching
- A powerful auto-complete engine with fuzzy matching.
- Multiple scoring models and sorting by values.
- Concurrent low-latency insertion and updates of documents.
- Concurrent searches allowing long-running queries without blocking Redis.
- An extension mechanism allowing custom scoring models and query extension.
- Support for indexing existing Hash objects in Redis databases.
Indexing documents
In order to search effectively, RediSearch needs to know how to index documents. A document may have several fields, each with its own weight (e.g. a title is usually more important than the text itself. The engine can also use numeric or geographical fields for filtering. Hence, the first step is to create the index definition, which tells RediSearch how to treat the documents we will add. For example, to define an index of products, indexing their title, description, brand, and price, the index creation would look like:
FT.CREATE my_index SCHEMA
title TEXT WEIGHT 5
description TEXT
brand TEXT
PRICE numeric
When we will add a document to this index, for example:
FT.ADD my_index doc1 1.0 FIELDS
title "Acme 42 inch LCD TV"
description "42 inch brand new Full-HD tv with smart tv capabilities"
brand "Acme"
price 300
This tells RediSearch to take the document, break each field into its terms ("tokenization") and index it, by marking the index for each of the terms in the index as contained in this document. Thus, the product is added immediately to the index and can now be found in future searches
Searching
Now that we have added products to our index, searching is very simple:
FT.SEARCH products "full hd tv"
This will tell RediSearch to intersect the lists of documents for each term and return all documents containing the three terms. Of course, more complex queries can be performed, and the full syntax of the query language is detailed below.
Data structures
RediSearch uses its own custom data structures and uses Redis' native structures only for storing the actual document content (using Hash objects).
Using specialized data structures allows faster searches and more memory effective storage of index records, utilizing compression techniques like delta encoding.
These are the data structures RediSearch uses under the hood:
For each search index, there is a root data structure containing the schema, statistics, etc - but most importantly, little compact metadata about each document indexed.
Internally, inside the index, RediSearch uses delta encoded lists of numeric, incremental, 32-bit document ids. This means that the user given keys or ids for documents, need to be replaced with the internal ids on indexing, and back to the original ids on search.
For that, RediSearch saves two tables, mapping the two kinds of ids in two ways (one table uses a compact trie, the other is simply an array where the internal document ID is the array index). On top of that, for each document, we store its user given a priory score, some status bits, and an optional "payload" attached to the document by the user.
Accessing the document metadata table is an order of magnitude faster than accessing the hash object where the document is actually saved, so scoring functions that need to access metadata about the document can operate fast enough.
Inverted index
For each term appearing in at least one document, we keep an inverted index, basically a list of all the documents where this term appears. The list is compressed using delta coding, and the document ids are always incrementing.
When the user indexes the documents "foo", "bar" and "baz" for example, they are assigned incrementing ids, For example 1025, 1045, 1080. When encoding them into the index, we only encode the first ID, followed by the deltas between each entry and the previous one, in this case, 1025, 20, 35.
Using variable-width encoding, we can use one byte to express numbers under 255, two bytes for numbers between 256 and 16383 and so on. This can compress the index by up to 75%.
On top of the ids, we save the frequency of each term in each document, a bit mask representing the fields in which the term appeared in the document, and a list of the positions in which the term appeared.
The structure of the default search record is as follows. Usually, all the entries are one byte long:
+----------------+------------+------------------+-------------+------------------------+
| docId_delta | frequency | field mask | offsets len | offset, offset, .... |
| (1-4 bytes) | (1-2 bytes)| (1-16 bytes) | (1-2 bytes)| (1-2 bytes per offset) |
+----------------+------------+------------------+-------------+------------------------+
Optionally, we can choose not to save any one of those attributes besides the ID, degrading the features available to the engine.
Numeric index
Numeric properties are indexed in a special data structure that enables filtering by numeric ranges in an efficient way. One could view a numeric value as a term operating just like an inverted index. For example, all the products with the price $100 are in a specific list, that is intersected with the rest of the query (see Query Execution Engine).
However, in order to filer by a range of prices, we would have to intersect the query with all the distinct prices within that range - or perform a union query. If the range has many values in it, this becomes highly inefficient.
To avoid that, we group numeric entries with close values together, in a single "range node". These nodes are stored in binary range tree, that allows the engine to select the relevant nodes and union them together. Each entry in a range node contains a document Id, and the actual numeric value for that document. To further optimize, the tree uses an adaptive algorithm to try to merge as many nodes as possible within the same range node.
Tag index
Tag indexes are similar to full-text indexes, but use simpler tokenization and encoding in the index. The values in these fields cannot be accessed by general field-less search and can be used only with a special syntax.
The main differences between tag fields and full-text fields are:
The tokenization is simpler: The user can determine a separator (defaults to a comma) for multiple tags, and we only do whitespace trimming at the end of tags. Thus, tags can contain spaces, punctuation marks, accents, etc. The only two transformations we perform are lower-casing (for latin languages only as of now), and whitespace trimming.
Tags cannot be found from a general full-text search. If a document has a field called "tags" with the values "foo" and "bar", searching for foo or bar without a special tag modifier (see below) will not return this document.
The index is much simpler and more compressed: we only store document ids in the index, usually resulting in 1-2 bytes per index entry.
Geo index
Geo indexes utilize Redis' own geo-indexing capabilities. In query time, the geographical part of the query (a radius filter) is sent to Redis, returning only the ids of documents that are within that radius. Longitude and latitude should be passed as one string lon,lat. For example, 1.23,4.56.
Auto-complete
The auto-complete engine (see below for a fuller description) utilizes a compact trie or prefix tree, to encode terms and search them by prefix.
Query language
We support a simple syntax for complex queries, that can be combined together to express complex filtering and matching rules. The query is combined as a text string in the FT.SEARCH request and is parsed using a complex query parser.
- Multi-word phrases simply a list of tokens, e.g.
foo bar baz, and imply intersection (AND) of the terms. - Exact phrases are wrapped in quotes, e.g
"hello world". - OR Unions (i.e
word1 OR word2), are expressed with a pipe (|), e.g. hello|hallo|shalom|hola. - NOT negation (i.e.
word1 NOT word2) of expressions or sub-queries. e.g. hello -world. - Prefix matches (all terms starting with a prefix) are expressed with a
* following a 2-letter or longer prefix. - Selection of specific fields using the syntax
@field:hello world. - Numeric Range matches on numeric fields with the syntax
@field:[{min} {max}]. - Geo radius matches on geo fields with the syntax
@field:[{lon} {lat} {radius} {m|km|mi|ft}] - Tag field filters with the syntax
@field:{tag | tag | ...}. See the full documentation on tag fields. - Optional terms or clauses:
foo ~bar means bar is optional but documents with bar in them will rank higher.
Complex queries example
Expressions can be combined together to express complex rules. For example, let's assume we have a database of products, where each entity has the fields title, brand, tags and price.
Expressing a generic search would be simply:
lcd tv
This would return documents containing these terms in any field. Limiting the search to specific fields (title only in this case) is expressed as:
@title:(lcd tv)
Numeric filters can be combined to filter price within a price range:
@title:(lcd tv)
@price:[100 500.2]
Multiple text fields can be accessed in different query clauses, for example, to select products of multiple brands:
@title:(lcd tv)
@brand:(sony | samsung | lg)
@price:[100 500.2]
Tag fields can be used to index multi-term properties without actual full-text tokenization:
@title:(lcd tv)
@brand:(sony | samsung | lg)
@tags:{42 inch | smart tv}
@price:[100 500.2]
And negative clauses can also be added, in this example to filter out plasma and CRT TVs:
@title:(lcd tv)
@brand:(sony | samsung | lg)
@tags:{42 inch | smart tv}
@price:[100 500.2]
-@tags:{plasma | crt}
Scoring model
RediSearch comes with a few very basic scoring functions to evaluate document relevance. They are all based on document scores and term frequency. This is regardless of the ability to use sortable fields (see below). Scoring functions are specified by adding the SCORER {scorer_name} argument to a search request.
If you prefer a custom scoring function, it is possible to add more functions using the Extension API.
These are the pre-bundled scoring functions available in RediSearch:
TFIDF (Default)
Basic TF-IDF scoring with document score and proximity boosting factored in.
TFIDF.DOCNORM
Identical to the default TFIDF scorer, with one important distinction:
BM25
A variation on the basic TF-IDF scorer, see this Wikipedia article for more info.
DISMAX
A simple scorer that sums up the frequencies of the matched terms; in the case of union clauses, it will give the maximum value of those matches.
DOCSCORE
A scoring function that just returns the priory score of the document without applying any calculations to it. Since document scores can be updated, this can be useful if you'd like to use an external score and nothing further.
Sortable fields
It is possible to bypass the scoring function mechanism, and order search results by the value of different document properties (fields) directly - even if the sorting field is not used by the query. For example, you can search for first name and sort by the last name.
When creating the index with FT.CREATE, you can declare TEXT and NUMERIC properties to be SORTABLE. When a property is sortable, we can later decide to order the results by its values. For example, in the following schema:
> FT.CREATE users SCHEMA first_name TEXT last_name TEXT SORTABLE age NUMERIC SORTABLE
Would allow the following query:
FT.SEARCH users "john lennon" SORTBY age DESC
Result highlighting and summarisation
Highlighting allows users to only the relevant portions of document matching a search query returned as a result. This allows users to quickly see how a document relates to their query, with the search terms highlighted, usually in bold letters.
RediSearch implements high performance highlighting and summarization algorithms, with the following API:
FT.SEARCH ...
SUMMARIZE [FIELDS {num} {field}] [FRAGS {numFrags}] [LEN {fragLen}] [SEPARATOR {separator}]
HIGHLIGHT [FIELDS {num} {field}] [TAGS {openTag} {closeTag}]
Summarisation will fragment the text into smaller sized snippets; each snippet will contain the found term(s) and some additional surrounding context.
Highlighting will highlight the found term (and its variants) with a user-defined tag. This may be used to display the matched text in a different typeface using a markup language, or to otherwise make the text appear differently.
Auto-completion
Another important feature for RediSearch is its auto-complete engine. This allows users to create dictionaries of weighted terms, and then query them for completion suggestions to a given user prefix. Completions can have "payloads" - a user-provided piece of data that can be used for display. For example, completing the names of users, it is possible to add extra metadata about users to be displayed al
For example, if a user starts to put the term “lcd tv” into a dictionary, sending the prefix “lc” will return the full term as a result. The dictionary is modeled as a compact trie (prefix tree) with weights, which is traversed to find the top suffixes of a prefix.
RediSearch also allows for Fuzzy Suggestions, meaning you can get suggestions to prefixes even if the user makes a typo in their prefix. This is enabled using a Levenshtein Automaton, allowing efficient searching of the dictionary for all terms within a maximal Levenshtein Distance of a term or prefix. Then suggestions are weighted based on both their original score and their distance from the prefix typed by the user.
However, searching for fuzzy prefixes (especially very short ones) will traverse an enormous number of suggestions. In fact, fuzzy suggestions for any single letter will traverse the entire dictionary, so we recommend using this feature carefully, in consideration of the performance penalty it incurs.
RediSearch's auto-completer supports Unicode, allowing for fuzzy matches in non-latin languages as well.
Search engine internals
The Redis module API
RediSearch utilizes the Redis Module API and is loaded into Redis as an extension module.
Redis modules make possible to extend Redis functionality, implementing new Redis commands, data structures and capabilities with similar performance to native core Redis itself. Redis modules are dynamic libraries, that can be loaded into Redis at startup or using the MODULE LOAD command. Redis exports a C API, in the form of a single C header file called redismodule.h.
This means that while the logic of RediSearch and its algorithms are mostly independent, and it could, in theory, be ported quite easily to run as a stand-alone server - it still "stands on the shoulders" of giants and takes advantage of Redis as a robust infrastructure for a database server. Building on top of Redis means that by default the module operates:
- A high performance network protocol server.
- Robust replication.
- Highly durable persistence as snapshots of transaction logs.
- Cluster mode.
- etc.
Query execution engine
RediSearch uses a high-performance flexible query processing engine, that can evaluate very complex queries in real time.
The above query language is compiled into an execution plan that consists of a tree of "index iterators" or "filters". These can be any of:
- Numeric filter
- Tag filter
- Text filter
- Geo filter
- Intersection operation (combining 2 or more filters)
- Union operation (combining 2 or more filters)
- NOT operation (negating the results of an underlying filter)
- Optional operation (wrapping an underlying filter in an optional matching filter)
The query parser generates a tree of these filters. For example, a multi-word search would be resolved into an intersect operation of multiple text filters, each traversing an inverted index of a different term. Simple optimizations such as removing redundant layers in the tree are applied.
Each of the filters in the resulting tree evaluates one match at a time. This means that at any given moment, the query processor is busy evaluating and scoring one matching document. This means that very little memory allocation is done at run-time, resulting in higher performance.
The resulting matching documents are then fed to a post-processing chain of "result processors", responsible for scoring them, extracting the top-N results, loading the documents from storage and sending them to the client. That chain is dynamic as well, and changes based on the attributes of the query. For example, a query that only needs to return document ids, will not include a stage for loading documents from storage.
Concurrent updates and searches
While it is extremely fast and uses highly optimized data structures and algorithms, it was facing the same problem with regards to concurrency: Depending on the size of your data-set and the cardinality of search queries, they can take internally anywhere between a few microseconds, to hundreds of milliseconds to seconds in extreme cases. And when that happens - the entire Redis server that the engine is running on - is blocked.
Think, for example, of a full-text query intersecting the terms "hello" and "world", each with, let's say, a million entries, and half a million common intersection points. To do that in a millisecond, you would have to scan, intersect and rank each result in one nanosecond, which is impossible with current hardware. The same goes for indexing a 1000 word document. It blocks Redis entirely for that duration.
RediSearch utilizes the Redis Module API's concurrency features to avoid stalling the server for long periods of time. The idea is simple - while Redis in itself still remains single-threaded, a module can run many threads - and any one of them can acquire the Global Lock when it needs to access Redis data, operate on it, and release it.
We still cannot really query Redis in parallel - only one thread can acquire the lock, including the Redis main thread - but we can make sure that a long-running query will give other queries time to properly run by yielding this lock from time to time.
To allow concurrency, we adopted the following design:
RediSearch has a thread pool for running concurrent search queries.
When a search request arrives, it gets to the handler, gets parsed on the main thread, and a request object is passed to the thread pool via a queue.
The thread pool runs a query processing function in its own thread.
The function locks the Redis Global lock and starts executing the query.
Since the search execution is basically an iterator running in a cycle, we simply sample the elapsed time every several iterations (sampling on each iteration would slow things down as it has a cost of its own).
If enough time has elapsed, the query processor releases the Global Lock, and immediately tries to acquire it again. When the lock is released, the kernel will schedule another thread to run - be it Redis' main thread, or another query thread.
When the lock is acquired again - we reopen all Redis resources we were holding before releasing the lock (keys might have been deleted while the thread has been "sleeping") and continue work from the previous state.
Thus the operating system's scheduler makes sure all query threads get CPU time to run. While one is running the rest wait idly, but since execution is yielded about 5,000 times a second, it creates the effect of concurrency. Fast queries will finish in one go without yielding execution, slow ones will take many iterations to finish, but will allow other queries to run concurrently.
Index garbage collection
RediSearch is optimized for high write, update and delete throughput. One of the main design choices dictated by this goal is that deleting and updating documents do not actually delete anything from the index:
- Deletion simply marks the document deleted in a global document metadata table, using a single bit.
- Updating, on the other hand, marks the document as deleted, assigns it a new incremental document ID, and re-indexes the document under a new ID, without performing a comparison of the change.
What this means, is that index entries belonging to deleted documents are not removed from the index, and can be seen as "garbage". Over time, an index with many deletes and updates will contain mostly garbage - both slowing things down and consuming unnecessary memory.
To overcome this, RediSearch employs a background Garbage Collection mechanism: during normal operation of the index, a special thread randomly samples indexes, traverses them and looks for garbage. Index sections containing garbage are "cleaned" and memory is reclaimed. This is done in a none intrusive way, operating on very small amounts of data per scan, and utilizing Redis' concurrency mechanism (see above) to avoid interrupting the searches and indexing. The algorithm also tries to adapt to the state of the index, increasing the garbage collector's frequency if the index contains a lot of garbage, and decreasing it if it doesn't, to the point of hardly scanning if the index does not contain garbage.
Extension model
RediSearch supports an extension mechanism, much like Redis supports modules. The API is very minimal at the moment, and it does not yet support dynamic loading of extensions in run-time. Instead, extensions must be written in C (or a language that has an interface with C) and compiled into dynamic libraries that will be loaded at run-time.
There are two kinds of extension APIs at the moment:
- Query Expanders, whose role is to expand query tokens (i.e. stemmers).
- Scoring Functions, whose role is to rank search results in query time.
Extensions are compiled into dynamic libraries and loaded into RediSearch on initialization of the module. In fact, the mechanism is based on the code of Redis' own module system, albeit far simpler.
Scalable Distributed Search
While RediSearch is very fast and memory efficient, if an index is big enough, at some point it will be too slow or consume too much memory. Then, it will have to be scaled out and partitioned over several machines - meaning every machine will hold a small part of the complete search index.
Traditional clusters map different keys to different “shards” to achieve this. However, in search indexes, this approach is not practical. If we mapped each word’s index to a different shard, we would end up needing to intersect records from different servers for multi-term queries.
The way to address this challenge is to employ a technique called Index Partitioning, which is very simple at its core:
- The index is split across many machines/partitions by document ID.
- Every such partition has a complete index of all the documents mapped to it.
- We query all shards concurrently and merge the results from all of them into a single result.
To enable that, a new component is added to the cluster, called a Coordinator. When searching for documents, the coordinator receives the query, and sends it to N partitions, each holding a sub-index of 1/N documents. Since we’re only interested in the top K results of all partitions, each partition returns just its own top K results. We then merge the N lists of K elements and extract the top K elements from the merged list.
8.3 - Garbage collection
Details about garbage collection
Garbage Collection in RediSearch
1. The Need For GC
- Deleting documents is not really deleting them. It marks the document as deleted in the global document table, to make it fast.
- This means that basically an internal numeric id is no longer assigned to a document. When we traverse the index we check for deletion.
- Thus all inverted index entries belonging to this document id are just garbage.
- We do not want to go and explicitly delete them when deleting a document because it will make this operation very long and depending on the length of the document.
- On top of that, updating a document is basically deleting it, and then adding it again with a new incremental internal id. We do not do any diffing, and only append to the indexes, so the ids remain incremental, and the updates fast.
All of the above means that if we have a lot of updates and deletes, a large portion of our inverted index will become garbage - both slowing things down and consuming unnecessary memory.
Thus we want to optimize the index. But we also do not want to disturb the normal operation. This means that optimization or garbage collection should be a background process, that is non intrusive. It only needs to be faster than the deletion rate over a long enough period of time so that we don't create more garbage than we can collect.
2. Garbage Collecting a Single Term Index
A single term inverted index is consisted of an array of "blocks" each containing an encoded list of records - document id delta plus other data depending on the index encoding scheme. When some of these records refer to deleted documents, this is called garbage.
The algorithm is pretty simple:
- Create a reader and writer for each block
- Read each block's records one by one
- If no record is invalid, do nothing
- Once we found a garbage record, we advance the reader but not the writer.
- Once we found at least one garbage record, we encode the next records to the writer, recalculating the deltas.
Pseudo code:
foreach index_block as block:
reader = new_reader(block)
writer = new_write(block)
garbage = 0
while not reader.end():
record = reader.decode_next()
if record.is_valid():
if garbage != 0:
# Write the record at the writer's tip with a newly calculated delta
writer.write_record(record)
else:
writer.advance(record.length)
else:
garbage += record.length
2.1 Garbage Collection on Numeric Indexes
Numeric indexes are now a tree of inverted indexes with a special encoding of (docId delta,value). This means the same algorithm can be applied to them, only traversing each inverted index object in the tree.
3. FORK GC
Information about FORK GC can be found in this blog
Since v1.6 the FORK GC is the default GC policy and was proven very efficient both in cleaning the index and not reduce query and indexing performance (even for a very write internsive use-cases)
8.4 - Document Indexing
This document describes how documents are added to the index.
Components
Document - this contains the actual document and its fields.RSAddDocumentCtx - this is the per-document state that is used while it
is being indexed. The state is discarded once completeForwardIndex - contains terms found in the document. The forward index
is used to write the InvertedIndex (later on)InvertedIndex - an index mapping a term to occurrences within applicable
documents.
Architecture
The indexing process begins by creating a new RSAddDocumentCtx and adding a
document to it. Internally this is divided into several steps.
Submission.
A DocumentContext is created, and is associated with a document (as received)
from input. The submission process will also perform some preliminary caching.
Preprocessing
Once a document has been submitted, it is preprocessed. Preprocessing performs
stateless processing on all document input fields. For text fields, this
means tokenizing the document and creating a forward index. The preprocesors
will store this information in per-field variables within the AddDocumentCtx.
This computed result is then written to the (persistent) index later on during
the indexing phase.
If the document is sufficiently large, the preprocessing is done in a separate
thread, which allows concurrent preprocessing and also avoids blocking other
threads. If the document is smaller, the preprocessing is done within the main
thread, avoiding the overhead of additional context switching.
The SELF_EXC_THRESHOLD (macro) contains the threshold for 'sufficiently large'.
Once the document is preprocessed, it is submitted to be indexed.
Indexing
Indexing proper consists of writing down the precomputed results of the
preprocessing phase above. It is done in a single thread, and is in the form
of a queue.
Because documents must be written to the index in the exact order of their
document ID assignment, and because we must also yield to other potential
indexing processes, we may end up in a situation where document IDs are written
to the index out-of-order. In order to solve that, the order in which documents
are actually written must be well-defined. If there is only one thread writing
documents, then this thread will not need to worry about out-of-order IDs
while writing.
Having a single background thread also helps optimize in several areas, as
will be seen later on. The basic idea is that when there are a lot of
documents queued for the indexing thread, the indexing thread may treat them
as batch commands, greatly reducing the number of locks/unlocks of the GIL
and the number of times term keys need to be opened and closed.
Skipping already indexed documents
The phases below may operate on more than one document at a time. When a document
is fully indexed, it is marked as done. When the thread iterates over the queue
it will only perform processing/indexing on items not yet marked as done.
Term Merging
Term merging, or forward index merging, is done when there is more than a
single document in the queue. The forward index of each document in the queue
is scanned, and a larger, 'master' forward index is constructed in its place.
Each entry in the forward index contains a reference to the origin document
as well as the normal offset/score/frequency information.
Creating a 'master' forward index avoids opening common term keys once per
document.
If there is only one document within the queue, a 'master' forward index
is not created.
Note that the internal type of the master forward index is not actually
ForwardIndex.
Document ID assignment
At this point, the GIL is locked and every document in the queue is assigned
a document ID. The assignment is done immediately before writing to the index
so as to reduce the number of times the GIL is locked; thus, the GIL is
locked only once - right before the index is written.
Writing to Indexes
With the GIL being locked, any pending index data is written to the indexes.
This usually involves opening one or more Redis keys, and writing/copying
computed data into those keys.
Once this is done, the reply for the given document is sent, and the
AddDocumentCtx freed.
9 - Indexing JSON documents
Indexing and searching JSON documents
In addition to indexing Redis hashes, RediSearch also indexes JSON. To index JSON, you must use the RedisJSON module.
Prerequisites
What do you need to start indexing JSON documents?
- Redis 6.x or later
- RediSearch 2.2 or later
- RedisJSON 2.0 or later
How to index JSON documents
This section shows how to create an index.
You can now specify ON JSON to inform RediSearch that you want to index JSON documents.
For the SCHEMA, you can provide JSONPath expressions.
The result of each JSON Path expression is indexed and associated with a logical name (attribute).
This attribute (previously called field) is used in the query.
This is the basic syntax to index a JSON document:
FT.CREATE {index_name} ON JSON SCHEMA {json_path} AS {attribute} {type}
And here's a concrete example:
FT.CREATE userIdx ON JSON SCHEMA $.user.name AS name TEXT $.user.tag AS country TAG
Adding a JSON document to the index
As soon as the index is created, any pre-existing JSON document, or any new JSON document added or modified, is
automatically indexed.
You can use any write command from the RedisJSON module (JSON.SET, JSON.ARRAPPEND, etc.).
This example uses the following JSON document:
{
"user": {
"name": "John Smith",
"tag": "foo,bar",
"hp": "1000",
"dmg": "150"
}
}
Use JSON.SET to store the document in the database:
JSON.SET myDoc $ '{"user":{"name":"John Smith","tag":"foo,bar","hp":1000, "dmg":150}}'
Because indexing is synchronous, the document will be visible on the index as soon as the JSON.SET command returns.
Any subsequent query matching the indexed content will return the document.
Searching
To search for documents, use the FT.SEARCH commands.
You can search any attribute mentioned in the SCHEMA.
Following our example, find the user called John:
FT.SEARCH userIdx '@name:(John)'
1) (integer) 1
2) "myDoc"
3) 1) "$"
2) "{\"user\":{\"name\":\"John Smith\",\"tag\":\"foo,bar\",\"hp\":1000,\"dmg\":150}}"
Field projection
FT.SEARCH returns the whole document by default.
You can also return only a specific attribute (name for example):
FT.SEARCH userIdx '@name:(John)' RETURN 1 name
1) (integer) 1
2) "myDoc"
3) 1) "name"
2) "\"John Smith\""
Projecting using JSON Path expressions
The RETURN parameter also accepts a JSON Path expression which lets you extract any part of the JSON document.
The following example returns the result of the JSON Path expression $.user.hp.
FT.SEARCH userIdx '@name:(John)' RETURN 1 $.user.hp
1) (integer) 1
2) "myDoc"
3) 1) "$.user.hp"
2) "1000"
Note that the property name is the JSON expression itself: 3) 1) "$.user.hp"
Using the AS option, you can also alias the returned property.
FT.SEARCH userIdx '@name:(John)' RETURN 3 $.user.hp AS hitpoints
1) (integer) 1
2) "myDoc"
3) 1) "hitpoints"
2) "1000"
Highlighting
You can highlight any attribute as soon as it is indexed using the TEXT type.
For FT.SEARCH, you have to explicitly set the attribute in the RETURN and the HIGHLIGHT parameters.
FT.SEARCH userIdx '@name:(John)' RETURN 1 name HIGHLIGHT FIELDS 1 name TAGS '<b>' '</b>'
1) (integer) 1
2) "myDoc"
3) 1) "name"
2) "\"<b>John</b> Smith\""
Aggregation with JSON Path expression
Aggregation is a powerful feature. You can use it to generate statistics or build facet queries.
The LOAD parameter accepts JSON Path expressions. Any value (even not indexed) can be used in the pipeline.
This example loads two numeric values from the JSON document applying a simple operation.
FT.AGGREGATE userIdx '*' LOAD 6 $.user.hp AS hp $.user.dmg AS dmg APPLY '@hp-@dmg' AS points
1) (integer) 1
2) 1) "point"
2) "850"
Current indexing limitations
JSON arrays can only be indexed in a TAG field.
It is only possible to index an array of strings or booleans in a TAG field.
Other types (numeric, geo, null) are not supported.
It is not possible to index JSON objects.
To be indexed, a JSONPath expression must return a single scalar value (string or number).
If the JSONPath expression returns an object, it will be ignored.
However it is possible to index the strings in separated attributes.
Given the following document:
{
"name": "Headquarters",
"address": [
"Suite 250",
"Mountain View"
],
"cp": "CA 94040"
}
Before you can index the array under the address key, you have to create two fields:
FT.CREATE orgIdx ON JSON SCHEMA $.address[0] AS a1 TEXT $.address[1] AS a2 TEXT
OK
You can now index the document:
JSON.SET org:1 $ '{"name": "Headquarters","address": ["Suite 250","Mountain View"],"cp": "CA 94040"}'
OK
You can now search in the address:
FT.SEARCH orgIdx "suite 250"
1) (integer) 1
2) "org:1"
3) 1) "$"
2) "{\"name\":\"Headquarters\",\"address\":[\"Suite 250\",\"Mountain View\"],\"cp\":\"CA 94040\"}"
Index JSON strings and numbers as TEXT and NUMERIC
- You can only index JSON strings as TEXT, TAG, or GEO (using the right syntax).
- You can only index JSON numbers as NUMERIC.
- Boolean and NULL values are ignored.
SORTABLE not supported on TAG
FT.CREATE orgIdx ON JSON SCHEMA $.cp[0] AS cp TAG SORTABLE
(error) On JSON, cannot set tag field to sortable - cp
With hashes, you can use SORTABLE (as a side effect) to improve the performance of FT.AGGREGATE on TAGs.
This is possible because the value in the hash is a string, such as "foo,bar".
With JSON, you can index an array of strings.
Because there is no valid single textual representation of those values,
there is no way for RediSearch to know how to sort the result.
10 - Chinese
Chinese support
Chinese support in RediSearch
Support for adding documents in Chinese is available starting at version 0.99.0.
Chinese support allows Chinese documents to be added and tokenized using segmentation
rather than simple tokenization using whitespace and/or punctuation.
Indexing a Chinese document is different than indexing a document in most other
languages because of how tokens are extracted. While most languages can have
their tokens distinguished by separation characters and whitespace, this
is not common in Chinese.
Chinese tokenization is done by scanning the input text and checking every
character or sequence of characters against a dictionary of predefined terms
and determining the most likely (based on the surrounding terms and characters)
match.
RediSearch makes use of the Friso
Chinese tokenization library for this purpose. This is largely transparent to
the user and often no additional configuration is required.
Example: Using Chinese in RediSearch
In pseudo-code:
FT.CREATE idx SCHEMA txt TEXT
FT.ADD idx docCn 1.0 LANGUAGE chinese FIELDS txt "Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]"
FT.SEARCH idx "数据" LANGUAGE chinese HIGHLIGHT SUMMARIZE
# Outputs:
# <b>数据</b>?... <b>数据</b>进行写操作。由于完全实现了发布... <b>数据</b>冗余很有帮助。[8...
Using the Python Client:
# -*- coding: utf-8 -*-
from redisearch.client import Client, Query
from redisearch import TextField
client = Client('idx')
try:
client.drop_index()
except:
pass
client.create_index([TextField('txt')])
# Add a document
client.add_document('docCn1',
txt='Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]',
language='chinese')
print client.search(Query('数据').summarize().highlight().language('chinese')).docs[0].txt
Prints:
<b>数据</b>?... <b>数据</b>进行写操作。由于完全实现了发布... <b>数据</b>冗余很有帮助。[8...
Using custom dictionaries
If you wish to use a custom dictionary, you can do so at the module level when
loading the module. The FRISOINI setting can point to the location of a
friso.ini file which contains the relevant settings and paths to the dictionary
files.
Note that there is no "default" friso.ini file location. RediSearch comes with
its own friso.ini and dictionary files which are compiled into the module
binary at build-time.




















